目录
Lucene 简介 简介
Lucene是一套用于全文检索和搜索的开放源码程序库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程序接口,能够做全文索引和搜索,在Java开发环境里Lucene是一个成熟的免费开放源代码工具;就其本身而论,Lucene是现在并且是这几年,最受欢迎的免费Java信息检索程序库。
Lucene 能够为文本类型的数据建立索引,所以你只要能把你要索引的数据格式转化的文本的,Lucene 就能对你的文档进行索引和搜索。比如你要对一些 HTML 文档,PDF 文档进行索引的话你就首先需要把 HTML 文档和 PDF 文档转化成文本格式的,然后将转化后的内容交给 Lucene 进行索引,然后把创建好的索引文件保存到磁盘或者内存中,最后根据用户输入的查询条件在索引文件上进行查询。不指定要索引的文档的格式也使 Lucene 能够几乎适用于所有的搜索应用程序。
现在很流行的Solr 和Elasticsearch ,都是基于Lucene 开发的.此外,Eclipse 的帮助系统的搜索也是基于Lucene实现的.
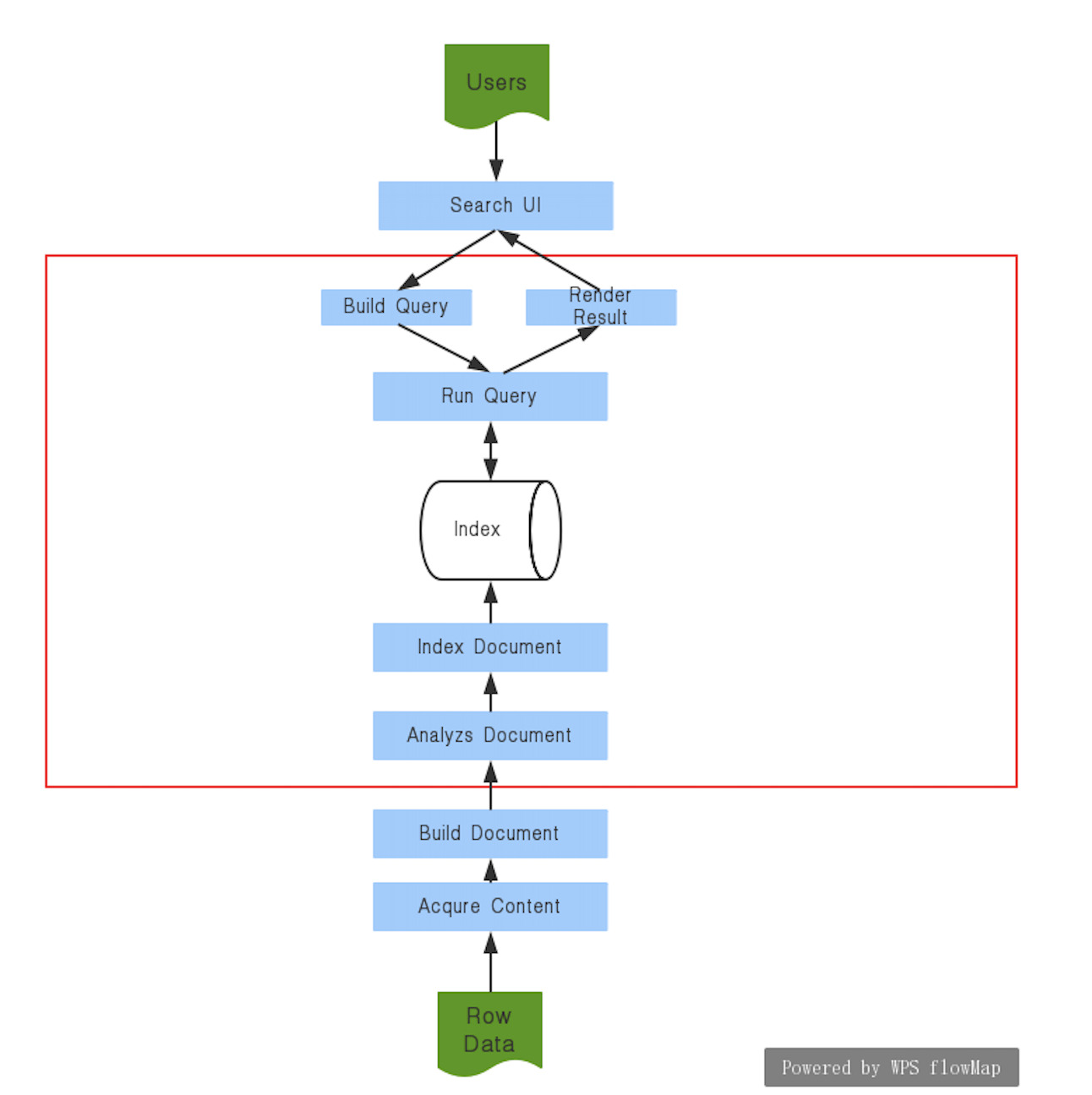
流程图 使用lucene构建的搜索程序的流程图如下(图源:Lucene In Action书中配图,博主绘制):
红框中的部分可以由Lucene完成,其余需要自己编码或者借助其他开源框架.
使用准备 简单的使用Lucene,只需要引入Jar包,然后编写对应的生成索引和查找代码即可.
在本文的示例中,我使用Lucene给我的博客建立一个简单的搜索系统,因为之前的搜索系统是在前端完成的,这次学习的Lucene正好可以拿来完成一个后端的搜索系统.
实现思路:
对博客目录下的所有已md结尾的文件建立索引.并将索引写在硬盘上的某个目录下.
提供重建索引的API,因为文章可能会修改,以及新增.
提供根据关键字查找的API.
根据查找API返回的结果在前端进行渲染.
第四步就不说了,我凑活写了一点JS代码,能够比较丑的渲染出来.
对应于上面的架构图,这里详细写一下博客搜索的实现方法:
Row Data为在磁盘上存储的博客文件.acqure content以及build document为自己编码实现,主要是扫面磁盘文件,并且将其转换成Lucene Document的格式.Analyzs Document使用了Lucene的分词机制,使用的分词器为IKAnalyzier.index document使用lucene的索引API.
然后是搜索过程:
search ui是由前端完成,直接传入搜索字符串.使用lucene分词机制对搜索词进行分词
调用lucene查询API,查询文件
调用lucene解析结果的API拿到结果,封装,返回至前端.
前端进行渲染.
添加依赖 使用Maven管理项目的话:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 <dependency > <groupId > org.apache.lucene</groupId > <artifactId > lucene-core</artifactId > <version > 8.0.0</version > </dependency > <dependency > <groupId > org.apache.lucene</groupId > <artifactId > lucene-queryparser</artifactId > <version > 8.0.0</version > </dependency > <dependency > <groupId > org.apache.lucene</groupId > <artifactId > lucene-highlighter</artifactId > <version > 8.0.0</version > </dependency > <dependency > <groupId > org.apache.lucene</groupId > <artifactId > lucene-analyzers-common</artifactId > <version > 8.0.0</version > </dependency >
建立索引代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public void create () throws IOException { if (deleteAllIndex()) { logger.info("clear the index." ); } else { logger.info("cleat the index error, stop create index." ); return ; } Directory d = FSDirectory.open(FileSystems.getDefault().getPath(indexPath)); logger.info("start create index for blog." ); Analyzer analyzer = new JcsegAnalyzer (1 ); IndexWriterConfig conf = new IndexWriterConfig (analyzer); IndexWriter indexWriter = new IndexWriter (d, conf); int curFileNum = FILE_NUM.get(); findFile(blogPath, indexWriter); logger.info("add {} file into index." , FILE_NUM.get() - curFileNum); indexWriter.close(); } private boolean deleteAllIndex () { File indexDir = new File (indexPath); if (indexDir.isDirectory()) { File[] files = indexDir.listFiles(); if (files == null || files.length == 0 ) { logger.info("index dir is em[ty." ); return true ; } for (File file : files) { if (!file.delete()) { logger.info("delete some index error, file = {}" , file.getAbsolutePath()); return false ; } } return true ; } logger.info("delete index error, because the file is not a dir." ); return false ; } private void findFile (String blogPath, IndexWriter indexWriter) throws IOException { File file = new File (blogPath); if (file.exists()) { File[] files = file.listFiles(); if (files == null || files.length == 0 ) { logger.info("this file is empty, path = {}" , file.getAbsolutePath()); } else { for (File file2 : files) { if (file2.isDirectory()) { logger.info(" {} is a directory, find in it." , file2.getAbsolutePath()); findFile(file2.getAbsolutePath(), indexWriter); } else { if (file2.getName().endsWith(".md" )) { logger.info("find a md file = {} , make index" , file2.getAbsolutePath()); FILE_NUM.incrementAndGet(); addFile(indexWriter, file2); } } } } } else { logger.warn("file is not exist" ); } } private void addFile (IndexWriter indexWriter, File file) throws IOException { Document doc = new Document (); String titleValue = file.getName().replace(".md" , "" ); IndexableField title = new TextField ("title" , titleValue, Field.Store.YES); String contentValue = readToString(file); IndexableField content = new TextField ( "content" , contentValue, Field.Store.YES); Map<String, List<String>> profiles = getTagsAndCategoriesFromContent(file, contentValue); List<String> tagList = profiles.get(TAGS_KEY); String tagStr = String.join("," , tagList); IndexableField tags = new TextField ("tags" , tagStr, Field.Store.YES); List<String> categoriesList = profiles.get(CATEGORIES_KEY); String categoriesStr = String.join("," , categoriesList); IndexableField categories = new TextField ("categories" , categoriesStr, Field.Store.YES); doc.add(title); doc.add(content); doc.add(tags); doc.add(categories); indexWriter.addDocument(doc); }
这里面主要实现了四个方法:
创建索引的入口
删除当前的所有索引
遍历查找文件
将查找到的文件读取并调用Lucene API建立索引.
查找API 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 public List<SearchArticleVO> search (String target) throws IOException { List<SearchArticleVO> result = new ArrayList <>(); String[] fields = {"title" , "tags" , "content" }; for (String field : fields) { paddingResultByField(target, result, field); if (result.size() >= 10 ) { break ; } } return result; } private void paddingResultByField (String target, List<SearchArticleVO> result, String field) throws IOException { Directory d = FSDirectory.open(FileSystems.getDefault().getPath(indexPath)); IndexReader indexReader = DirectoryReader.open(d); IndexSearcher indexSearcher = new IndexSearcher (indexReader); Query query = new TermQuery (new Term (field, target)); TopDocs topDocs = indexSearcher.search(query, 100 ); logger.info("search keyword = {}, getNum = {}" , target, topDocs.totalHits); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { logger.info("score = {}" , scoreDoc.score); int doc = scoreDoc.doc; Document document = indexSearcher.doc(doc); String title = document.get("title" ).substring(11 ); logger.info("get article name = {}" , title); String tagStr = document.get("tags" ); String content = document.get("content" ); String categoriesStr = document.get("categories" ); List<String> tagList = Stream.of(tagStr.split("," )).collect(Collectors.toList()); List<String> caList = Stream.of(categoriesStr.split("," )).collect(Collectors.toList()); String cateUrl = String.join("/" , caList) + "/" ; String dateUrl = document.get("title" ).substring(0 , 11 ).replace("-" , "/" ); String url = "http://huyan.couplecoders.tech/" + cateUrl.toLowerCase() + dateUrl + title; int firstIndex = content.indexOf(target); String targetStr = content.substring(firstIndex - 15 < 0 ? 0 : firstIndex - 15 , firstIndex + 15 > content.length() ? content.length() - 1 : firstIndex + 15 ).replaceAll("\n" , "" ); result.add(SearchArticleVO.builder() .title(title).content(content) .tags(tagList) .url(url) .categories(caList) .targetStr(targetStr) .build()); } } private Map<String, List<String>> getTagsAndCategoriesFromContent (File file, String content) { Map<String, List<String>> map = new HashMap <>(); Pattern r = Pattern.compile("---\n.*---\n" , Pattern.CASE_INSENSITIVE | Pattern.DOTALL); Matcher m = r.matcher(content); if (m.find()) { String s = m.group(); List<String> tags = new ArrayList <>(); Pattern p1 = Pattern.compile("- .*\n" ); Matcher m1 = p1.matcher(s); while (m1.find()) { tags.add(m1.group(0 ).replace("\n" , "" ).replace("- " , "" )); } map.put(TAGS_KEY, tags); logger.info("load {} tags from {} done." , tags.size(), file.getAbsolutePath() + file.getName()); List<String> categories = new ArrayList <>(); Pattern p2 = Pattern.compile("category:.*\n" ); Matcher m2 = p2.matcher(s); while (m2.find()) { List<String> tmp = Stream.of(m2.group() .replace("category: " , "" ) .replace("]" , "" ) .replace("\n" , "" ) .replace("[" , "" ) .split("," )).collect(Collectors.toList()); categories.addAll(tmp); } map.put(CATEGORIES_KEY, categories); logger.info("load {} categories from {} done." , categories.size(), file.getAbsolutePath() + file.getName()); } else { logger.warn("not match tags or categories from {}, warning." , file.getAbsolutePath() + file.getName()); } return map; }
这里主要实现的是:
根据传入嗯关键字进行查找,然后获取真正的内容进行返回.
返回的时候需要拼装多个字段,在上面的代码中有很大一部分进行了这个操作.
实现的效果 这个是纯后端的一个项目,实现的效果较为难以量化.
体验地址
在博客的SEARCH 页面中添加了入口,可以输入关键字进行搜索.
搜索效率比较高,我在后台实际测试在毫秒级.
关于重建索引的说明 Lucene其实是支持增量的添加索引的,否则在数据量极其大的情况下,每次都全量的重建索引是不科学的.
但是在本文中,我采用的是每次清空索引,全部重建,原因主要有以下:
我的数据量很小,1k篇文章最多了.
我只是写个Demo,增量添加索引打算后续研究以下.
每次不止是添加文章,还可能对已有的文章进行了一些修改,所以在这个情况下的增量添加索引我没整明白.
存在的问题
就像上面写的,需要解决增量添加索引的问题,全量更新不是长久之计.
我测试的效率还不错,但是远没有达到预期,因为在我的数据量下需要100ms,那么在真正的应用场景中,这个延迟肯定是不能接受的,所以还有优化的空间.
Lucene的Collector功能十分丰富,应该是有提供更科学一点的方式来进行结果数据的组装,我现在的手动组装太愚蠢了.
Lucene应该支持目标内容高亮,目前我在前端实现的目标高亮算法实在是…,所以需要切换一下高亮内容的获取方法.
这些问题将在后续的文章中一一解决.
参考文章 Lucene-维基百科
基于Java的全文检索引擎简介
完。
ChangeLog
2019-04-07 完成
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客——>呼延十