public V put(K key, V value) { if (value == null) thrownewNullPointerException(); return doPut(key, value, false); }
/** * Main insertion method. Adds element if not present, or * replaces value if present and onlyIfAbsent is false. * @param key the key * @param value the value that must be associated with key * @param onlyIfAbsent if should not insert if already present * @return the old value, or null if newly inserted */ /** * 插入的主方法,如果不存在则插入元素,如果存在且传入的`onlyIfAbsent`为false则替换掉值. */ private V doPut(K key, V value, boolean onlyIfAbsent) { Node<K,V> z; // added node if (key == null) thrownewNullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { // 找到前置节点,在base-level上的. for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { if (n != null) { Object v; int c; Node<K,V> f = n.next; // 发生了多线程竞争,break.重新试一遍 if (n != b.next) // inconsistent read break; if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } if (b.value == null || v == n) // b is deleted break; // 如果key大于前置节点,继续 if ((c = cpr(cmp, key, n.key)) > 0) { b = n; n = f; continue; } // 等于则赋值 if (c == 0) { if (onlyIfAbsent || n.casValue(v, value)) { @SuppressWarnings("unchecked")Vvv= (V)v; return vv; } // 竞争失败了,重新来 break; // restart if lost race to replace value } // else c < 0; fall through } // 如果该前置节点的后继节点为空,则直接进行插入,使用cas操作连接传入的节点. z = newNode<K,V>(key, value, n); if (!b.casNext(n, z)) break; // restart if lost race to append to b break outer; } }
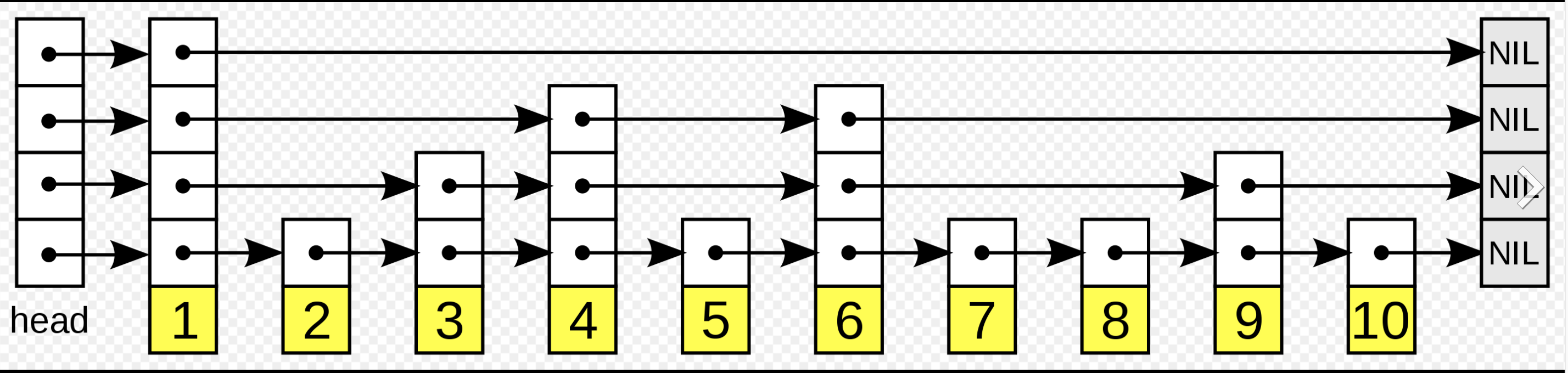
// 获取level intrnd= ThreadLocalRandom.nextSecondarySeed(); if ((rnd & 0x80000001) == 0) { // test highest and lowest bits intlevel=1, max; while (((rnd >>>= 1) & 1) != 0) ++level; Index<K,V> idx = null; HeadIndex<K,V> h = head; // 添加z的索引数据 if (level <= (max = h.level)) { for (inti=1; i <= level; ++i) idx = newIndex<K,V>(z, idx, null); } else { // 添加新的一层索引 level = max + 1; // hold in array and later pick the one to use @SuppressWarnings("unchecked")Index<K,V>[] idxs = (Index<K,V>[])newIndex<?,?>[level+1]; for (inti=1; i <= level; ++i) idxs[i] = idx = newIndex<K,V>(z, idx, null); for (;;) { h = head; intoldLevel= h.level; if (level <= oldLevel) // lost race to add level break; HeadIndex<K,V> newh = h; Node<K,V> oldbase = h.node; for (intj= oldLevel+1; j <= level; ++j) newh = newHeadIndex<K,V>(oldbase, newh, idxs[j], j); if (casHead(h, newh)) { h = newh; idx = idxs[level = oldLevel]; break; } } } // find insertion points and splice in splice: for (intinsertionLevel= level;;) { intj= h.level; for (Index<K,V> q = h, r = q.right, t = idx;;) { if (q == null || t == null) break splice; if (r != null) { Node<K,V> n = r.node; // compare before deletion check avoids needing recheck intc= cpr(cmp, key, n.key); if (n.value == null) { if (!q.unlink(r)) break; r = q.right; continue; } if (c > 0) { q = r; r = r.right; continue; } }
if (j == insertionLevel) { if (!q.link(r, t)) break; // restart if (t.node.value == null) { findNode(key); break splice; } if (--insertionLevel == 0) break splice; }
if (--j >= insertionLevel && j < level) t = t.down; q = q.down; r = q.right; } } } returnnull; }
/** * Gets value for key. Almost the same as findNode, but returns * the found value (to avoid retries during re-reads) * * @param key the key * @return the value, or null if absent */ private V doGet(Object key) { if (key == null) thrownewNullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { // 寻找前置节点 for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; // 如果为空则不存在,直接返回 if (n == null) break outer; Node<K,V> f = n.next; // 多线程竞争,重新试一下 if (n != b.next) // inconsistent read break; if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } if (b.value == null || v == n) // b is deleted break; // 如果相等,则返回值. if ((c = cpr(cmp, key, n.key)) == 0) { @SuppressWarnings("unchecked")Vvv= (V)v; return vv; } if (c < 0) break outer; b = n; n = f; } } returnnull; }
/** * Returns a base-level node with key strictly less than given key, * or the base-level header if there is no such node. Also * unlinks indexes to deleted nodes found along the way. Callers * rely on this side-effect of clearing indices to deleted nodes. * @param key the key * @return a predecessor of key */ private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) { if (key == null) thrownewNullPointerException(); // don't postpone errors for (;;) { // 拿到矩形索引的左上角的索引 for (Index<K,V> q = head, r = q.right, d;;) { // 右侧索引不为空 if (r != null) { Node<K,V> n = r.node; Kk= n.key; // 竞争 if (n.value == null) { if (!q.unlink(r)) break; // restart r = q.right; // reread r continue; } // 如果小于传入的key,则向右查找. if (cpr(cmp, key, k) > 0) { q = r; r = r.right; continue; } } // 到达最后一层了,数据层,返回拿到的节点.就是后继几点. if ((d = q.down) == null) return q.node; // 这边是右侧的索引为空,则可以直接向下一层了. q = d; r = d.right; } } }
/** * Main deletion method. Locates node, nulls value, appends a * deletion marker, unlinks predecessor, removes associated index * nodes, and possibly reduces head index level. * * Index nodes are cleared out simply by calling findPredecessor. * which unlinks indexes to deleted nodes found along path to key, * which will include the indexes to this node. This is done * unconditionally. We can't check beforehand whether there are * index nodes because it might be the case that some or all * indexes hadn't been inserted yet for this node during initial * search for it, and we'd like to ensure lack of garbage * retention, so must call to be sure. * * @param key the key * @param value if non-null, the value that must be * associated with key * @return the node, or null if not found */ final V doRemove(Object key, Object value) { if (key == null) thrownewNullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { // 寻找前置节点 for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; // 竞争 if (n == null) break outer; Node<K,V> f = n.next; if (n != b.next) // inconsistent read break; if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } if (b.value == null || v == n) // b is deleted break; // 如果节点不存在,直接返回 if ((c = cpr(cmp, key, n.key)) < 0) break outer; if (c > 0) { b = n; n = f; continue; } // 不删除了 if (value != null && !value.equals(v)) break outer; // 进行删除操作 if (!n.casValue(v, null)) break; // 删除索引 if (!n.appendMarker(f) || !b.casNext(n, f)) findNode(key); // retry via findNode else { findPredecessor(key, cmp); // clean index // 如果一层索引都空了,则删除这一层. if (head.right == null) tryReduceLevel(); } @SuppressWarnings("unchecked")Vvv= (V)v; return vv; } } returnnull; }