Redis 提供了很多精巧的独立功能,本文介绍 HyperLogLog, 它可以称作唯一性统计的利器了。
首先设想一个非常常见的业务需求,统计接口 uv, 应该怎么做。在日常的工作中,大部分情况下我们是走离线大数据那一套东西,将数据通过 kafka 等发送,之后导入 hive, 从 hive 中用 distinct来查找。
有没有别的方法呢?HyperLogLog帮你。
目录
介绍
首先贴一段官网介绍的译文:
HyperLogLog 是一种概率数据结构,用于计算惟一的事物(技术上这指的是估计集合的基数)。通常计算惟一项需要使用与要计算的项数量成比例的内存,因为您需要记住在过去已经看到的元素,以避免重复计算它们。然而,有一组算法用内存交换精度:以一个标准误差的估计度量。在 Redis 实现的情况下,这个标准误差小于 1%。这个算法的神奇之处在于,您不再需要使用与计数项数量成比例的内存,而是可以使用恒定数量的内存!最坏的情况是 12k 字节,如果您的 HyperLogLog(我们现在就称它们为 HLL) 只有很少的元素,消耗的内存也会少很多。
说人话就是:HyperLogLog 是一个内存消耗极少的,统计唯一值的计数器,可以将它理解为内存消耗极少的 Set. 因为它不会记住每一个元素的实际值。.
简单使用
相关命令
PFADD: 添加一个或者多个元素。PFADD key1 v1 v2 v3.O(1).
PFCOUNT: 返回不重复的元素的个数,可以统计多个 key. 同时,返回值是有一定 (0.81%) 错误率的近似值。PFCOUNT key1 key2 key3.O(n).
PFMERGE: 将多个 key 的内容合并到一个 key 中。PFMERGE target key1 key2.O(n),n 是 key 的数量。
redis 客户端示例
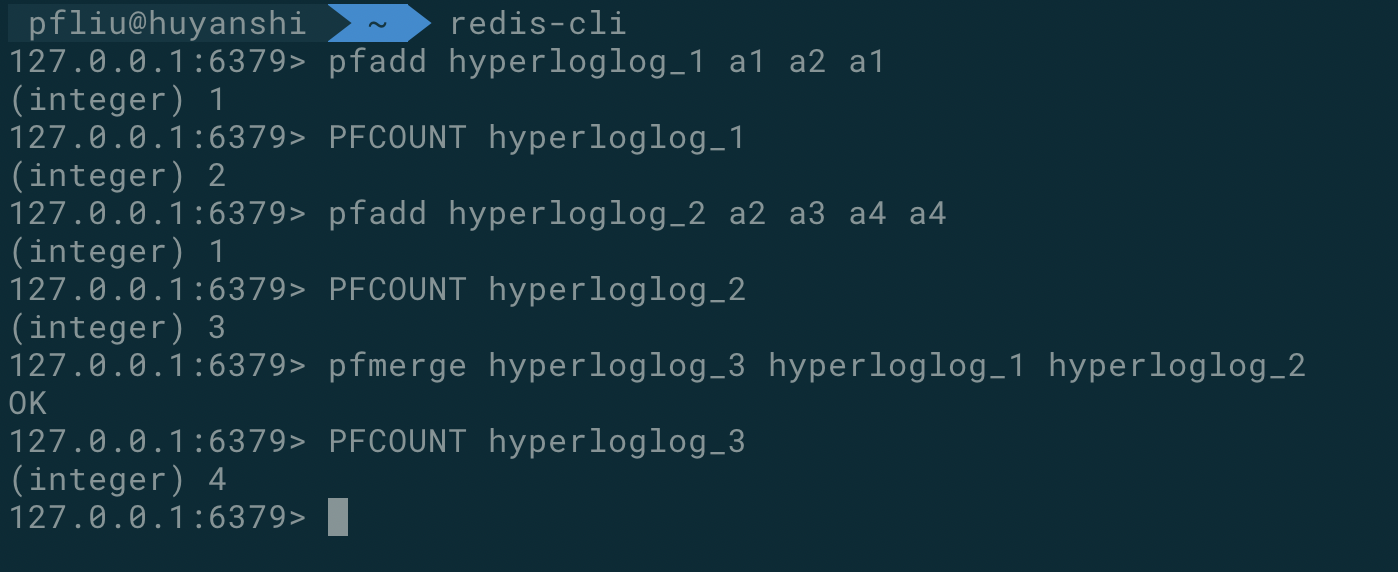
上面通过一些简单的操作,测试了上面提到的几个命令。
Java 代码示例
1
2
3
4
5
6
7
8
9
10
| public static void main(String [] args){
JedisPool pool = new JedisPool("localhost");
try (Jedis jedis = pool.getResource()) {
Long pfadd = jedis.pfadd("huyanshi", "item1", "item2", "item3");
System.out.println(pfadd);
long count = jedis.pfcount("huyanshi");
System.out.println(count);
}
}
|
Python 代码示例
1
2
3
4
5
6
| import redis
client = redis.StrictRedis()
client.pfadd("huyanshi", "item1", "item2")
total = client.pfcount("huyanshi")
print(total)
|
实现原理
对 HyperLogLog的使用,并没有太多需要注意的地方,比较简单粗暴。
但是它的实现却很精巧,在正常情况下,我们想要实现去重功能,需要一个 Set 来保存所有已有的元素,否则我们无从知道新的元素是否已经出现过。但是这样的内存消耗却是比较大的,而且比较浪费,因为我们只想要是否唯一这个结果,对于具体的值并不是很关心。
对于 Hyperloglog这个数据结构的原理,怎么推导出来我还真不知道,我们就直接说答案然后实验验证吧。
给定一定数量的随机数,低位连续零位的最大长度 k, 与随机数的数量 N , 有函数关系,大概为:K 和 N 的对数之间存在显著的线性相关性。即:N=2^K(约等于).
下面我们做个实现来验证一下。python 脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import math
import random
def low_zeros(value):
for i in range(1, 32):
if value >> i << i != value:
break
return i - 1
class BitKeeper(object):
def __init__(self): self.maxbits = 0
def random(self):
value = random.randint(0, 2 ** 32 - 1)
bits = low_zeros(value)
if bits > self.maxbits:
self.maxbits = bits
class Experiment(object):
def __init__(self, n):
self.n = n
self.keeper = BitKeeper()
def do(self):
for i in range(self.n):
self.keeper.random()
def debug(self):
print(self.n, '%.2f' % math.log(self.n, 2), self.keeper.maxbits)
for i in range(1000, 100000, 1000):
exp = Experiment(i)
exp.do()
exp.debug()
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| 36400 15.15 13
36500 15.16 16
36600 15.16 13
36700 15.16 14
36800 15.17 15
36900 15.17 18
37000 15.18 16
37100 15.18 15
37200 15.18 13
37300 15.19 14
37400 15.19 16
37500 15.19 14
37600 15.20 15
|
从中可以大概的看出,是 K 与 N 的对数之间有线性相关的, 但是误差太大了… 我们对每一次实验,记录多个 BitKeeper, 之后取他们的平均值试一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| import math
import random
def low_zeros(value):
for i in range(1, 32):
if value >> i << i != value: break
return i - 1
class BitKeeper(object):
def __init__(self):
self.maxbits = 0
def random(self, m):
bits = low_zeros(m)
if bits > self.maxbits:
self.maxbits = bits
class Experiment(object):
def __init__(self, n, k=1024):
self.n = n
self.k = k
self.keepers = [BitKeeper() for i in range(k)]
def do(self):
for i in range(self.n):
m = random.randint(0, 1 << 32 - 1)
keeper = self.keepers[((m & 0xfff0000) >> 16) % len(self.keepers)]
keeper.random(m)
def estimate(self):
sumbits_inverse = 0
for keeper in self.keepers:
sumbits_inverse += 1.0 / float(keeper.maxbits)
avgbits = float(self.k) / sumbits_inverse
return 2 ** avgbits * self.k
for i in range(100000, 1000000, 100000):
exp = Experiment(i)
exp.do()
est = exp.estimate()
print(i, '%.2f' % est, '%.2f' % (abs(est - i) / i))
|
输出结果如下:
1
2
3
4
5
6
7
8
9
| 100000 90526.76 0.09
200000 183057.33 0.08
300000 293629.48 0.02
400000 400516.22 0.00
500000 501280.71 0.00
600000 606538.41 0.01
700000 735047.95 0.05
800000 833842.57 0.04
900000 890712.83 0.01
|
可以看到,在我们加大了数据量以及去了 1024 个值的平均值之后,效果好了很多,预测结果的误差都比较小了。
当然,Redis 中HyperLogLog的实现远比上面写的要复杂,也要更加准确的多,我们使用了 1024 个桶来求平均值,Redis 中使用了16384个,
每个桶的 maxBits 需要 6 个 bit 来存储(可以表示 2 的 6 次方,也就是 64 位,就是 long 的长度), 所以每个HyperLogLog结构需要的空间为:16384 * 64 / 8 = 12k 字节.
从这里可以看出,无论我们向 HyperLogLog 中添加多少数据,它使用的空间是基本恒定的,当然,在数据量很小的时候,Redis 进行了一些额外的优化,来减少使用的内存。
需要注意的是,在 Redis 中,HyperLogLog 虽然在技术上使用不同的数据结构,但是被编码为一个 Redis 字符串,因此可以调用 GET 来序列化 HyperLogLog,并设置为将其反序列化回服务器。
应用场景
目前来讲,HyperLogLog比较适合使用在一些应用级别,接口级别的非精确唯一性统计上,比如统计当前某个页面的 uv, 某个接口的请求 uv 等等,而不是特别适合为每个用户进行统计,可以计算一下,每个用户需要 12k 字节的时候,如果你有 1 亿用户,那么内存使用量也比较夸张了。
参考文章
《Redis 深度历险:核心原理和应用实践》
Redis 官网
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

