前言
lucene在6.0之后引入了数字点(Point)的概念,对于多维数字点的索引,就需要用到kd树结构了,当然,在lucene中用到的是进阶版本的bkd树.
为了让自己不是一脸懵逼的去看lucene代码,这篇文章先大概学习一下kd树相关的基础理论知识.
kd树
k-d树,全称是k-dimensional树,也就是k维树.
k-d树是每个叶子节点都为k维点的二叉树。所有非叶子节点可以视作用一个超平面把空间分割成两个半空间。节点左边的子树代表在超平面左边的点,节点右边的子树代表在超平面右边的点。选择超平面的方法如下:每个节点都与k维中垂直于超平面的那一维有关。因此,如果选择按照x轴划分,所有x值小于指定值的节点都会出现在左子树,所有x值大于指定值的节点都会出现在右子树。这样,超平面可以用该x值来确定,其法线为x轴的单位向量。
kd树是所有BSP树中最常用的一种公共结构,它允许节点内部有任意的维度的数据. kd树使用二叉树实现,类似于一个BST。 关键的不同是,当每个节点比较大小时,可以使用不同的维度来比较. 下图是一个2k树的结构,它使用了不同的维度来划分左右区域.

类似于二叉搜索树,如果一个kd树是平衡的,可以保证O(logn) 的时间复杂度,因此每一个节点都把整个集合划分成了两半. 关键的问题就是,只有平衡的情况下才能保证这一点.设想一下,给途中的kd树,添加两个节点(1,1) ,(0,0), 整棵树的所有节点几乎已经全部在左侧了,这样就破坏了原有的平衡。更复杂的是,对于kd树而言,没有一些标准的技术来让树恢复平衡,比如树的旋转等操作. 我们能做的就是完全的重建这棵树,Scapegoat Tree就是这么做的.
1 | 因此,标准的kd树对于动态的更新,不提供很好的性能,只有在静态数据集上,kd树才有很好的性能. |
kdb树
接下来的进阶版本是KDB树. 他的全程不是k-dimensional Balance树`哦, 而是k-dimensional B树`. 这种数据结构,就是你混合了kd树和b+树之后会拿到的结构.
和标准的kd树一样,一个内部节点将空间分为两半. 和kd树不一样的是,内部节点不存储他们自己的数据. 空间内两个点定义个区域。每个维度的第一个点定义了最小值第二个点定义了最大值.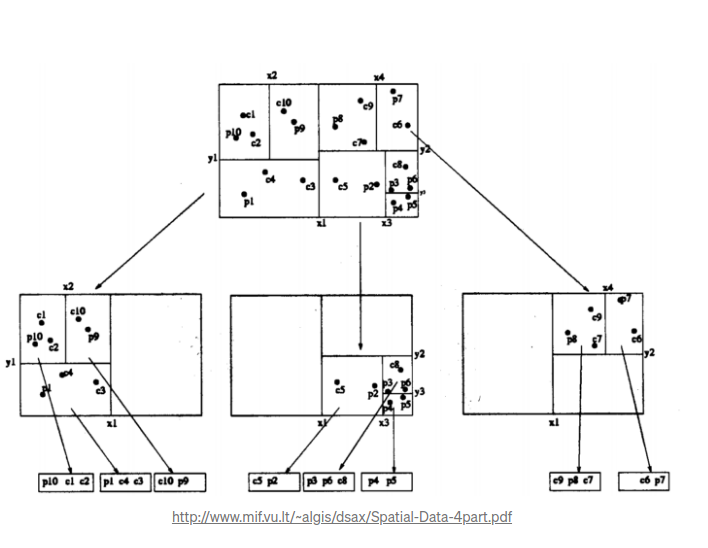
由于kdb树存储表现是一颗B树,他在磁盘上的性能很好. 这是因为提高了每个节点的扇出率,导致节点变大以及树变矮. 磁盘通常有高的延迟及高的吞吐量,这意味着读取大的数据块是有优势的,因为读取晓得数据块将话费更多的时间在延迟上。树比较低,意味着需要更少的逻辑读取. 在磁盘上,一个b树的节点的大小至少是和一个页一样大,也就是4k.更多的时间是大于这个值的. 因此,一个节点经常有成百上千个孩子节点.
像其他b树的变种一样,kdb树保证自身是平衡的树. 这是通过插入策略来保证的,如果一个插入元素在叶子节点上,且这个叶子节点没满, 那么将这个元素添加到这个叶子节点。如果叶子节点是满的,那就分裂. 不是通常想象的, 将值写入到树的高层节点上,而是只给高层节点添加一个区域。 如果一个元素在区域之外,事情就更复杂了。
试想一下,我们想在要在左边的底层区域做一个垂直的切割,由于这里有4个区域,因此他的父区域也需要切割,这意味着我们在切割整个左边的空间. 这是kdb树的主要缺点. 切割一个区域,通常需要切割他的孩子节点。 这个改动修改了树的大部分,如果此时我们需要写入磁盘,那么就会变得很慢.
kdb树的另外一个缺点是空间利用率,由于没有约束节点的大小,可能有很大的一部分空间都浪费了。这不仅影响磁盘页的大小,还会导致更少的页被缓存到内存中。
bkd树
bkd树用来解决空间问题和插入的效率问题. bkd树由多个修改后的kd树和独特的插入方法构成的. 下图是一个bkd树的基础结构.
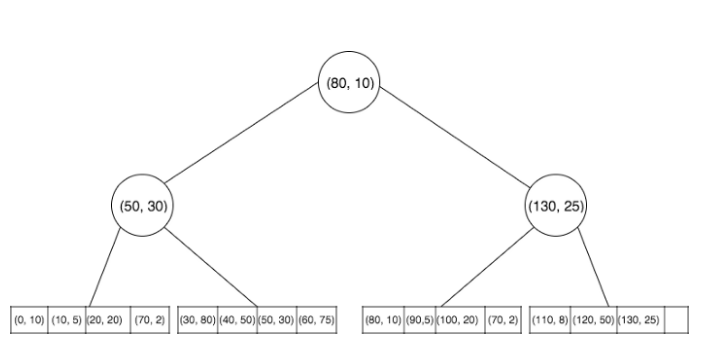
这个树由一个二叉树和一个b+树构成,特殊的是,内部节点必须是一个完全二叉树.
因为这是一颗完全二叉树,因此节点不需要记录子节点的指针,而是可以通过完全二叉树的性质算出来. 更小的节点意味着可以有更多的节点被缓存在内存.同时, 可以让大量的节点是叶子节点,这有效的降低了树的整体高度.
一个更大的因素,也是bkd最令人感兴趣的地方时,这些内部节点不会被更改,bkd树使用了一个聪明的办法来添加新的节点.
刚开始时,内存中缓存M个元素,这个缓冲区通常是一个简单的数组,因此他有很好的查询性能, 论文中没有特别说明这个缓冲区的大小,但是按照常识来猜测, 应该也是大于kd树的数量的.
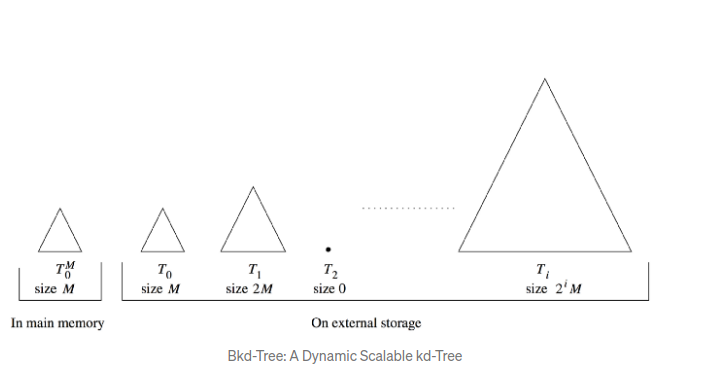
给定一个有N个节点的bkd树, 就有 log2(n/m)个改良的kd树. 每一个树的节点是上一个树的两倍. 对于bkd的插入,新节点直接进入缓冲区. 如果缓冲区满了,找到第一个不存在的kd树. 将内存区域中的所有数字,及之前树里的所有数字,一起用来构造这颗新树,将它填充为一颗完全二叉树. 论文中讲了一个构建树的快速方法,这里就不讲了.
这个方法看起来并不高效,但是在进一步评估之后,确实很高效. 下面是评估结果.
bkd树性能评估.
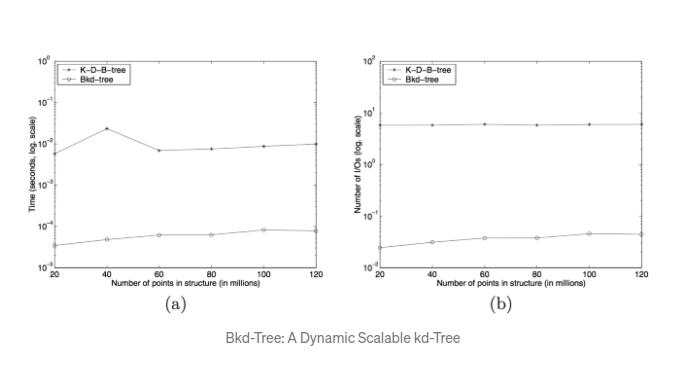
对于插入操作, bkd树比kdb树快两个数量级. 对于一个120亿数字的集合来说,插入消耗的时间平均是50微秒. 这非常令人深刻,尤其是使用的硬件还很差劲.
We used a dedicated Dell PowerEdge 2400 workstation with one Pentium III/500MHz processor, running FreeBSD 4.3. A 36GB SCSI disk (IBM Ultrastar 36LZX) was used to store all necessary files: the input points, the data structure, and the temporary files. The machine had 128MB of memory, but we restricted the amount of memory that TPIE could use to 64MB.
简单的说,bkd树就是快. 当我们观察插入操作是,大部分都直接进入了缓冲区, 直接命中ram而不是cpu的缓存. 更令人感兴趣的部分是树的构建和写入过程.
构造过程比较敖贵,因为连续的磁盘写入也不能避免大量的数据被移动了. 事实上,按照上面的例子说,至少可以支持60以的节点,看起来还贵吗?
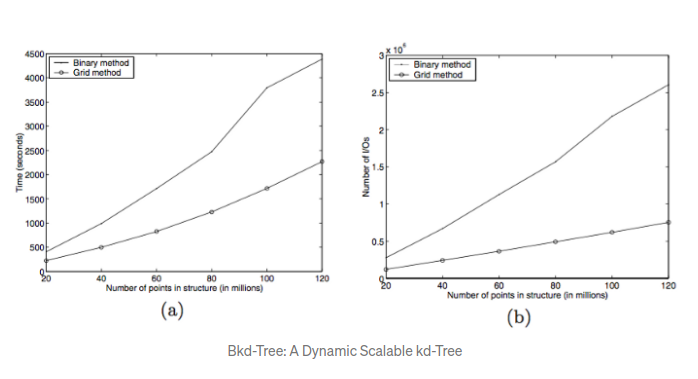
根据基准测试得出的结论,一次插入将要花费10min,这看起来十个坏消息但是记住下面这几点:
- 这是一个非常老的硬件,如果你用现代处理器和SSDs,那么完全不一样.
- 这是非常罕见的操作,这种操作不会经常发生,如上所示,他的实际吞吐量很高.
- 即使正在写入,数据仍然是可以被读取和查询的. 插入没有改变任何的现有的树结构,直到新树完全建成. io和缓存的竞争可能导致一点的慢读取,但是一定不会阻塞住.
如果要我猜,插入在现代的硬件上不会是一个问题,除非你要求的实时写入,我将会用我自己的基准测试来更新这篇文章.当我实现了这个结构的时候.
在这个树上查询是非常简单的,效率是稍微低一些的. 查询必须在所有的改良kd树上以及内存中的缓冲上各自进行一次,这是比kdb树慢一些,但是不是数量级的差距. 因为树都比较小. 这图是一个特别大的范围查询消耗的时间.
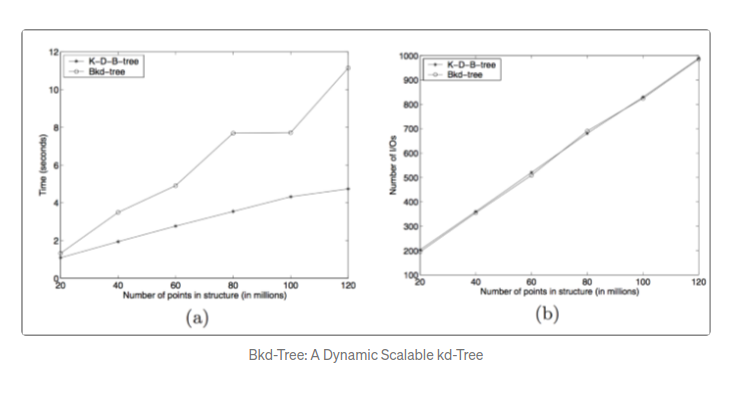
简单的查询应该很快很多,但是论文中没有写这一点. 如果范围的性能是你最关心的点,那么bkd树可能不是你最应该选择的数据结构.
最后,来看看空间利用率的问题,我们期待bkd树接近于完美. 这个是说明了空间效率的真实数据.
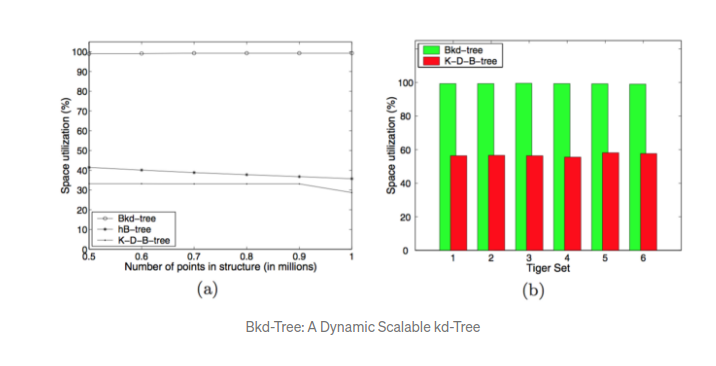
论文中没有提供一个紧凑的节点删除的方法,这比较令人担心,随着删除的节点越来越多,叶子的空间使用率会降低.
结论
总之呢,bkd树是一个特殊的数据结构,理论上平摊了写入成本. 因此写入会比较快。
参考文章
- https://zh.wikipedia.org/wiki/K-d%E6%A0%91
- 本文部分翻译于: https://medium.com/@nickgerleman/the-bkd-tree-da19cf9493fb
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十

