本文使用 Lucene 代码版本:8.7.0
前言
本文学习kdi文件格式.
他又是经典三个文件中的存储索引的文件.
.kdi 文件整体结构
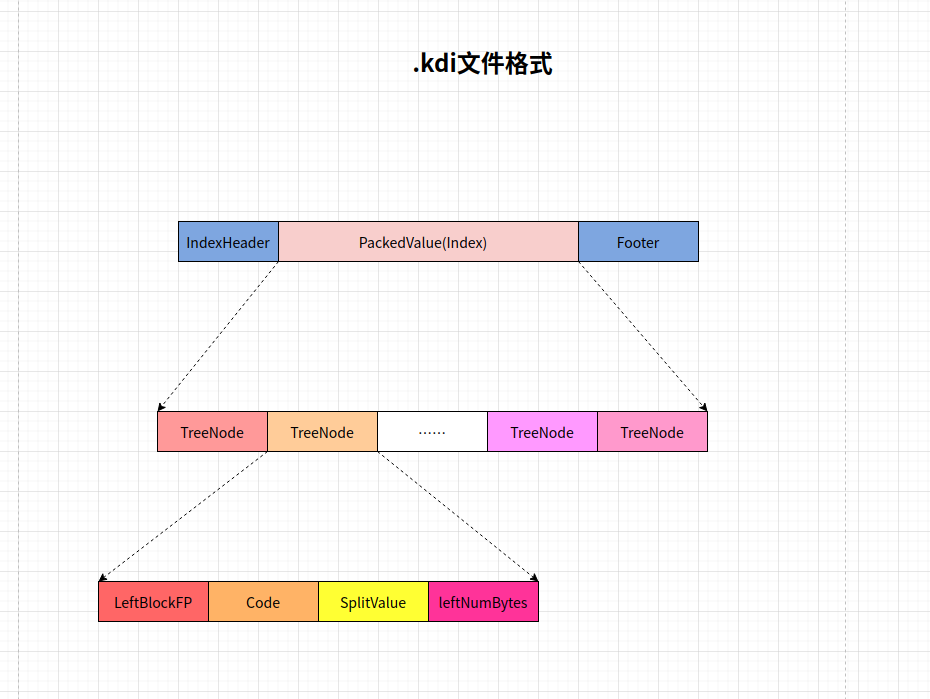
字段解释:
PackedValue: 其实我更愿意叫他Index. 他是整个完全二叉树的内部节点集合.
采用先序遍历的方式,存储在一个字节数组(每个字节数组是一个Node)的数组中.
TreeNode: 树的内部节点.实现不一定完全相同. 主要可能包含以下部分.
- LeftBlockFP: 这个参数不是一直存储的,如果当前节点是父节点的左儿子,则不存储。如果是父节点的右儿子,则存储下
以当前节点为根的子树中,最左节点与当前节点的父节点为根的树中,最左节点的文件偏移增量. - code:
code是一个逻辑计算的值,公式如下:
int code = (firstDiffByteDelta * (1 + config.bytesPerDim) + prefix) * config.numIndexDims + splitDim;
其中:
- firstDiffByteDelta: 前非叶节点的划分值与上一个非叶节点的划分值第一个不相同的字节位置偏移
- config.bytesPerDim: 每一个维度的字节长度
- prefix:当前非叶节点的划分值与上一个非叶节点的划分值相同前缀的字节数
- numIndexDims: 点数据的索引维度
- splitDim: 当前分割节点的分割维度
- SplitValue: 切割点的值
- leftNumBytes: 当前节点的左子树的总字节长度,可以用来快速定位到当前节点的右子树。在搜索过程中,如果我们只需要递归右子树,那么这个值有用,可以快速定位过去.
相关写入代码分析
对于文件的写入,在org.apache.lucene.util.bkd.BKDWriter#writeIndex(org.apache.lucene.store.IndexOutput, org.apache.lucene.store.IndexOutput, int, int, byte[], long)中.
但是只有最后一行是实际的写入.
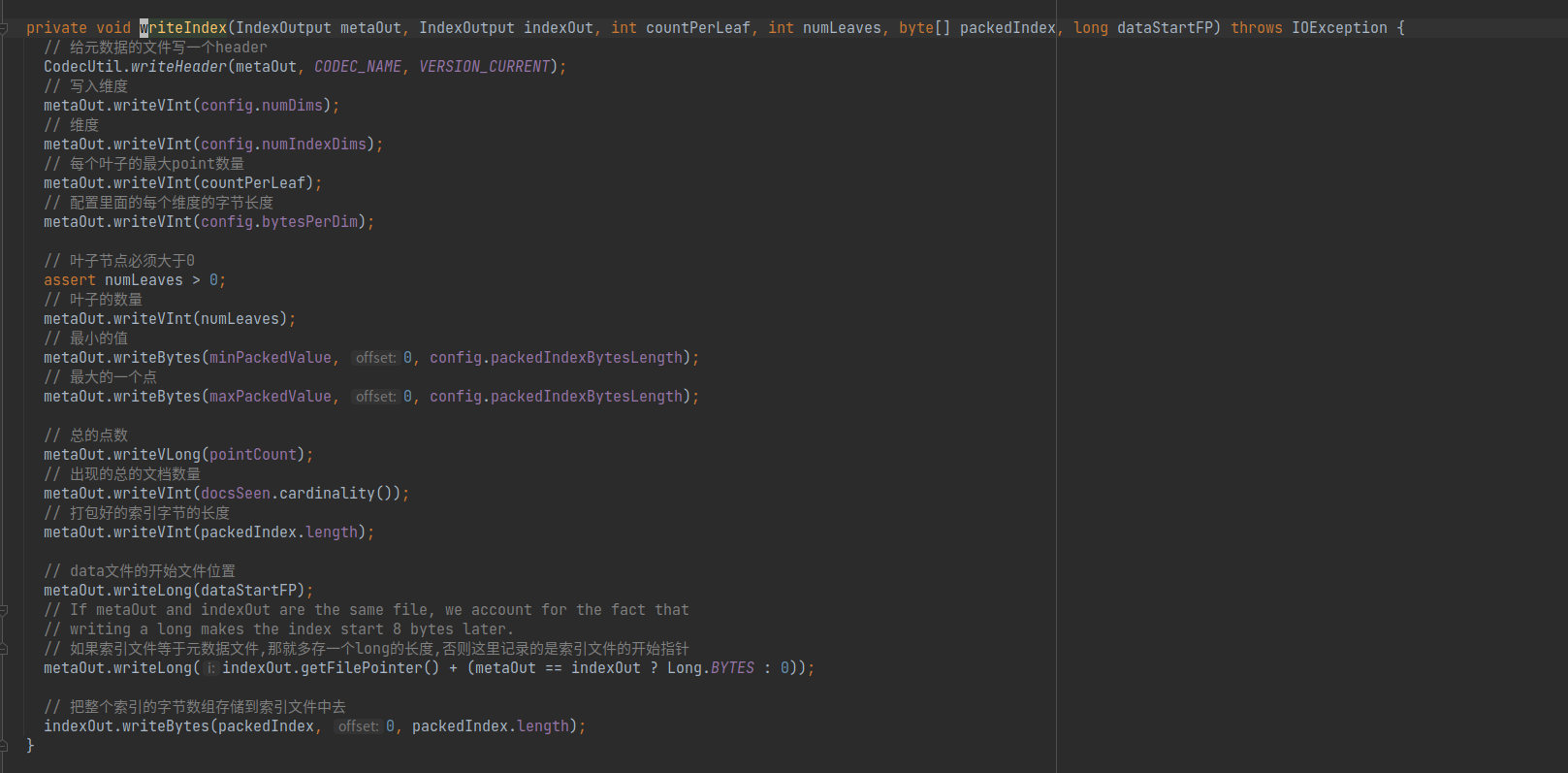
而事实上对于索引(也就是树的整体结构的生成代码)在org.apache.lucene.util.bkd.BKDWriter.packIndex中,
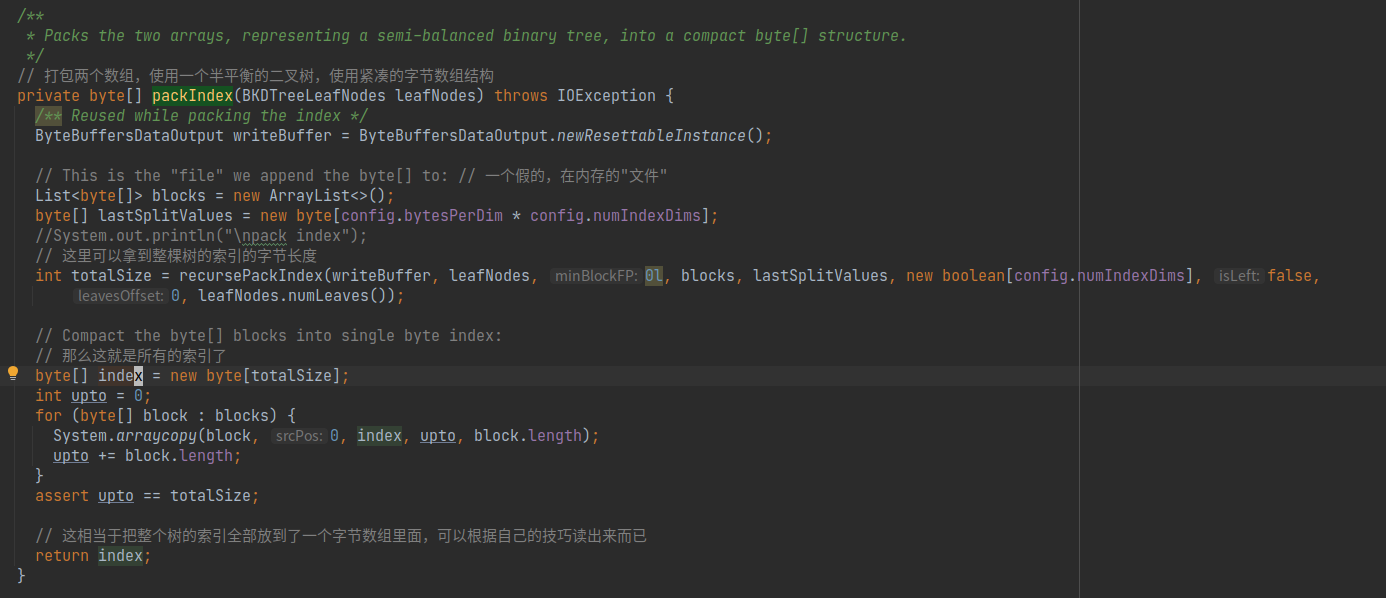
该方法对已排序好的叶子节点进行递归构建搜索二叉树,最后将二叉树进行前序列表进行输出,生成一个字节数组,方便存储到文件。
其中递归构造二叉树的逻辑在org.apache.lucene.util.bkd.BKDWriter.recursePackIndex中,由于代码过长, 且是比较经典的构造二叉树代码,这里就不贴了。
需要注意的是,内部节点的结构不一定完全一致,为了方便的遍历右子树,额外存储了一些信息,比如右节点上存储了该节点到最左节点的文件偏移量,根节点上存储了左子树的总字节长度等等.
结语
不是特别透彻,先放着,后续优化.
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

