前言
最近在做一些意图识别方面的工作,所以尝试一下用 fasttext 做一个文本分类器,学习记录如下。
简介
首先,我们使用 fasttext 的目的是什么?是文本分类,即对一个词语,给出它所属于的类别。
文本分类的目标是将文档(如电子邮件,博文,短信,产品评论等)分为一个或多个类别。 这些类别可以是根据评论分数,垃圾邮件与非垃圾邮件来划分,或者文档的编写语言。 如今,构建这种分类器的主要方法是机器学习,即从样本中学习分类规则。 为了构建这样的分类器,我们需要标注数据,它由文档及其相应的类别(也称为标签或标注)组成。
什么是 fasttext 呢?
FastText 是 Facebook 开源的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,精度接近深度模型但是速度更快。
原理
原理这部分要跳过了,因为网上的原理文章特别多,如果各位感兴趣的话可以移步 google 搜索或者文末相关文章。我在那里放了几个链接。
至于本文,首先网上的原理文章讲的普遍都不错。其次我对原理的了解程度完全不能让我在这里清楚的写出来,毕竟我只是个可怜的工程师。实现它,干上线才是我的宿命。
实际应用
首先要理解,fasttext 只是一个工具包,怎么使用它,用什么方式来实现它都是可选的。这里我选择的是使用命令行来训练模型,之后用 java 语言提供在线服务。当然你可以选择使用各种语言来进行训练和服务,因为有多种语言的 fasttext 包。
下载安装
我们可以直接下载正式发布的某个版本,
1 |
|
我个人更加推荐直接 clone 它在 github 上的项目,即执行:
1 | git clone git@github.com:facebookresearch/fastText.git |
之后进入他的目录,执行 make 即可。
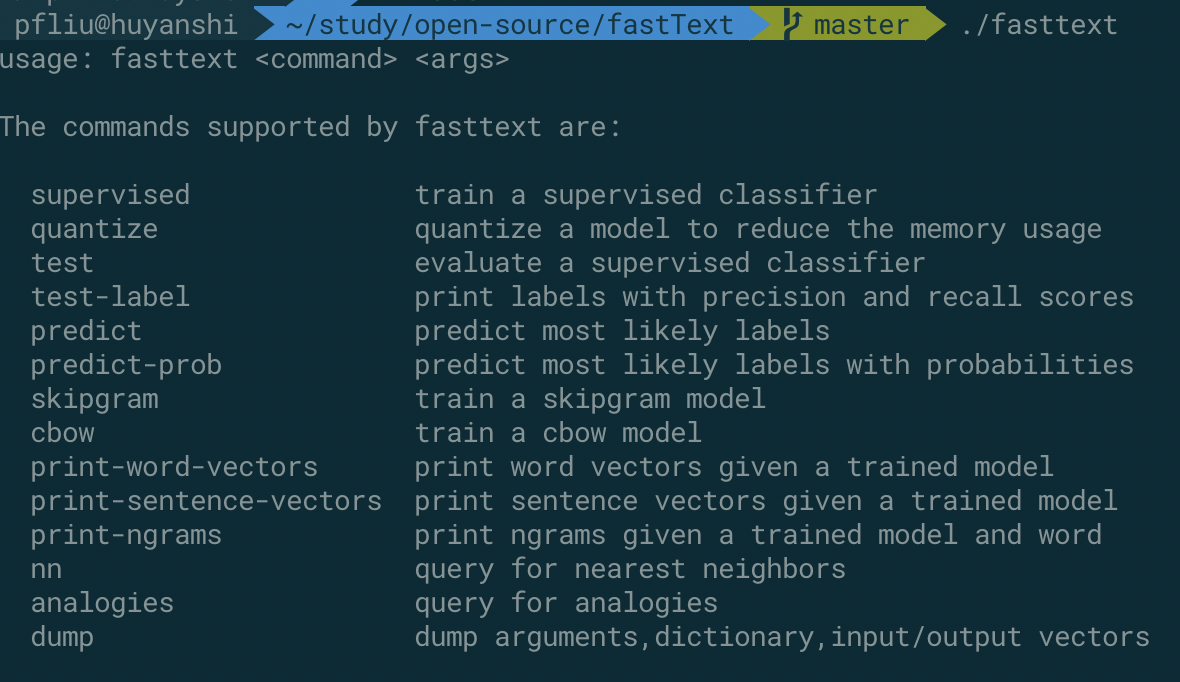
安装完毕之后,可以直接执行不带任何参数的命令,可以获取相关的帮助手册。
处理数据
官网的教程是使用 传送门 的一部分数据进行训练,这当然可以,但是我觉得大家可能更想看一些中文的训练样本。
首先给大家介绍一下训练样本的格式。如下:
1 | __label__name 呼 延 十 |
文本文件的每一行都包含一条训练样本,其后是相应的文档。 所有标签都以 label 前缀开始,这就是 fastText 如何识别标签或单词是什么。 然后对模型进行训练,以预测给定文档的标签。
注意,当你生成你的样本之后,需要区分开训练集和测试集,一般情况下我们使用训练:测试=8:2的比例。
我个人的训练样本中,包含城市名 (area), 人名 (name), 以及其他一些标签。训练样本 4 千万条,测试样本 1 千万条。基本上使用已经确定的一些词典生成。为了提升效果,样本尽可能准确,且数量尽量多一些。
训练
执行下面的命令,然后你会看到类似于下面的输出,等待运行完成(其中 input 是你的训练数据,output 是你输出的模型文件名称):
1 | ./fasttext supervised -input data.train -output model_name |
训练完成之后,你可以这样运行你的测试集来查看一些关键指标:
其中 test 之后紧接着是你的模型文件以及测试数据集。下面的指标是精确率和召回率。这个在后面解释。
1 | ./fasttext test model_name.bin data.test |
为了直观的测试一些常见 case 的结果,我们可以运行命令,交互式的进行一些测试。我的一些测试如下: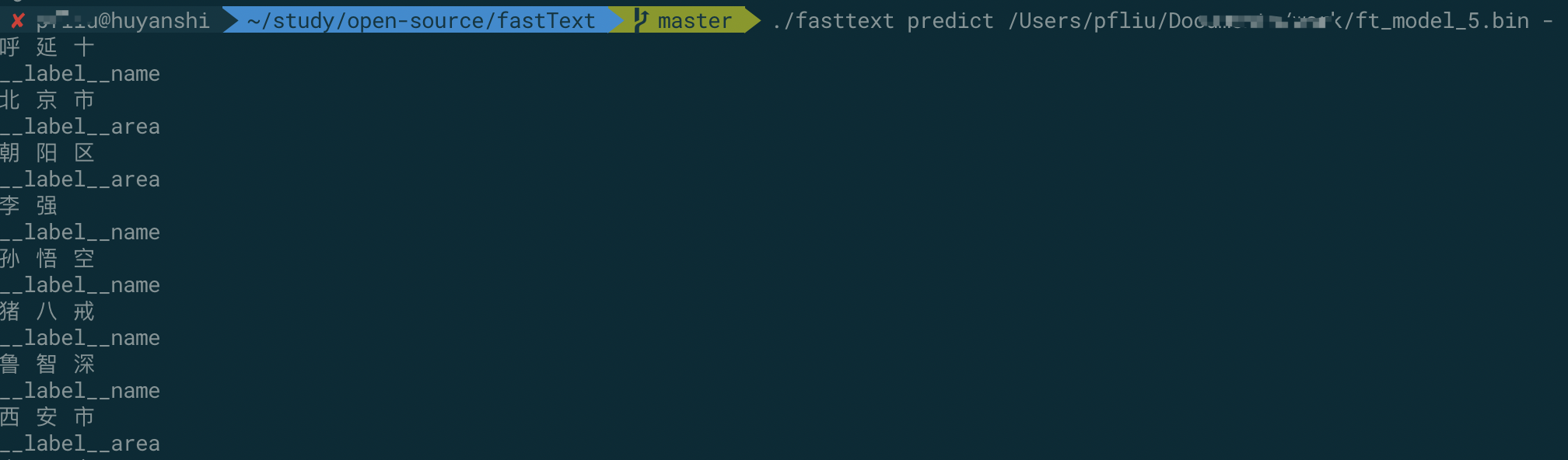
.
调优
首先这是对精确度和召回率的定义。
1 | 精确度是由 fastText 所预测标签中正确标签的数量。 召回率是所有真实标签中被成功预测出的标签数量。 我们举一个例子来说明这一点: |
毫无疑问,不论我们的目的是不是识别多个标签,这两个数值我们都要尽量高一些。
优化样本
我们的样本是程序生成的,这样理论上来说不能保证正确,最好是人工标注,当然人工标注千万级别的数据比较难,那么我们至少应该对样本进行一些基本的清理,比如单字去掉,符号去掉,统一小写等等操作。只要是与你的分类无关的数据理论上都应该去掉。
更多的迭代和更好的学习速率
简而言之,就是一些运行参数的变化,我们让程序训练更多轮,且更优的学习速率,加上这两个参数-lr 1.0 -epoch 25 , 当然你可以根据实际情况进行不断的调整及测试。
使用 n-gram
这是一个额外提高,在刚才的模型中,训练的时候是没有加上n-gram特征的,也就是没有考虑词序的因素。这里可以 简单了解 n-gram.
这是最终执行的训练命令:
1 |
|
这是我在我的测试集上的精确率和召回率:
1 | N 10997060 |
经过以上几个简单的步骤,识别准确度已经到了 98.5%, 这其实是一个不错的效果了,因为我目前没有确定是否使用这个方案来进行实际应用,所以到了 98.5%之后也没有继续进行优化了,如果后续有优化,我会来更新这篇文章。将所用到的优化方法记录下来。
demo
首先我们在 pom 文件中引入:
1 | <dependency> |
然后简单的写一下就好了:
1 | import com.github.jfasttext.JFastText; |
python 代码,更加简单了:
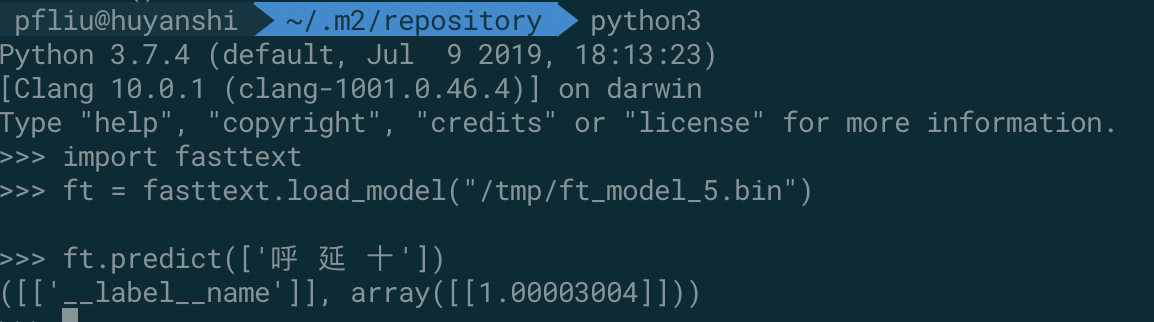
当然记得先安装一下:pip3 install fasttext.
相关文章
完。
ChangeLog
2019-11-17 完成
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

