本文源码已经上传至 github.: https://github.com/HuBlanker/Keras-Chinese-NER
本文主要理论依据论文:Bidirectional LSTM-CRF Models for Sequence Tagging
前言 命名实体识别(Named Entity Recognition,简称 NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。简单的讲,就是识别自然文本中的实体指称的边界和类别。
NER 是 NLP 领域的一个经典问题,在文本情感分析,意图识别等领域都有应用。它的实现方式也多种多样,从最早基于规则和词典,到传统机器学习到现在的深度学习。本文采用当前的经典解决方案,基于深度学习的 BiLSTM-CRF 模型来解决 NER 问题。
本文主要依据于 Bidirectional LSTM-CRF Models for Sequence Tagging 论文,并参考 github 上部分项目,实现了 基于 BilSTM-CRF 的中文文本命名实体识别,以用作 搜索中的意图识别。
我的目的是,使用 中文样本训练模型,然后在线提供预测,用于线上的搜索服务。所以本文可能对原理的介绍比较少,主要集中于 实际操作。对于 用 BiLSTM-CRF 来实现 NER 概念尚不清楚的同学,可以点击上方的论文了解一下,或者自行搜索了解。
离线训练 训练过程分为以下几个部分:
处理样本数据。
编写代码,包括数据处理,加载,模型搭建等。
实际训练并评估模型。
那么让我们来一步一步的解决这些问题。首先是样本数据部分。
样本数据 我们采用的格式是 字符-label. 也就是如下面这样,每个字符和其标签一一对应,句子与句子之间用空行隔开。
这里数据中的所有标签是常见的 地名, 人名, 机构名 标签,其中 B-LOC对应着一个地名的开始,O-LOC对应着一个地名的中间部分。O代表未识别部分,也就是Other. 其他的以此类推。
通过这样的数据,我们可以 拿到每一个实体的边界,进行切分之后就可以拿到有效的实体识别数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 6 O 月 O 油 O 印 O 的 O 《 O 北 B-LOC 京 I-LOC 文 O 物 O 保 O 存 O 保 O 管 O 状 O 态 O 之 O 调 O 查 O 报 O 告 O 》 O , O 调 O 查 O 范 O 围 O 涉 O 及 O 故 B-LOC 宫 I-LOC 、 O 历 B-LOC 博 I-LOC 、 O 古 B-ORG 研 I-ORG 所 I-ORG 、 O 北 B-LOC 大 I-LOC 清 I-LOC 华 I-LOC 图 I-LOC 书 I-LOC 馆 I-LOC 、 O 北 B-LOC 图 I-LOC 、 O 日 B-LOC 伪 O 资 O 料 O
我本人使用的样本是自己生成及标注的一部分,涉及到个人数据,不方便放到 github 中,因此 github 中仅有一个数据集的格式示例。
需要强调的是:对于 BiLSTM-CRF 模型解决 NER 问题来讲,理论已经在论文中说的十分明白,模型搭建代码网上也是有很多不错的可以使用的代码。
那么,重中之重就是样本的整理,当然这是一个逐步优化的过程,我们可以使用一部分样本来训练,之后逐步标注,或者用其他方式生成一些正确的样本。
训练 在 github 仓库里,有完整的可用于训练的代码,我进行了脱敏,但是完全不影响理解及执行。这里仅大致的贴一下核心代码。
数据编码 首先是对数据进行编码的代码,通过对所有训练数据 char 级别的编码,来让模型可以”认识” 我们的数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Word2Id : def __init__ (self, file ): self.file = file def gen_save (self ): data_file = [args.train_data, args.test_data] all_char = [] for f in data_file: file = open (f, "rb" ) data = file.read().decode("utf-8" ) data = data.split("\n\n" ) data = [token.split("\n" ) for token in data] data = [[j.split() for j in i] for i in data] data.pop() all_char.extend([char[0 ] if char else 'unk' for sen in data for char in sen]) chars = set (all_char) word2id = {char: id_ + 1 for id_, char in enumerate (chars)} word2id["unk" ] = 0 with open (self.file, "wb" ) as f: f.write(json.dumps(word2id, ensure_ascii=False ).encode('utf-8' )) def load (self ): return json.load(open (self.file, 'r' ))
模型搭建 2.1.4 版本的 keras,在 keras 版本里面已经包含 bilstm 模型,CRF 模型包含在 keras-contrib 中。
代码不难,且加了一些关键注释,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class Ner : def __init__ (self, vocab, labels_category, Embedding_dim=200 ): self.Embedding_dim = Embedding_dim self.vocab = vocab self.labels_category = labels_category self.model = self.build_model() def build_model (self ): model = Sequential() model.add(Embedding(len (self.vocab), self.Embedding_dim, mask_zero=True )) model.add(Bidirectional(LSTM(100 , return_sequences=True ))) crf = CRF(len (self.labels_category), sparse_target=True ) model.add(crf) model.summary() model.compile ('adam' , loss=crf.loss_function, metrics=[crf.accuracy]) return model def train (self, data, label, EPOCHS ): self.model.fit(data, label, batch_size=args.batch_size, callbacks=[CallBack()], epochs=EPOCHS) def retrain (self, model_path, data, label, epoch ): model = self.load_model_fromfile(model_path) print ("load model, evaluate it." ) loss, accuracy = model.evaluate(data, label) print ("load model, loss = %s, acc =%s ." % (loss, accuracy)) model.fit(data, label, batch_size=124 , callbacks=[CallBack()], epochs=epoch) def load_model_fromfile (self, model_path ): crf = CRF(len (self.labels_category), sparse_target=True ) return load_model(model_path, custom_objects={"CRF" : CRF, 'crf_loss' : crf.loss_function, 'crf_viterbi_accuracy' : crf.accuracy}) def predict (self, model_path, data, maxlen ): model = self.model char2id = [self.vocab.get(i) for i in data] input_data = pad_sequences([char2id], maxlen) model.load_weights(model_path) result = model.predict(input_data)[0 ][-len (data):] result_label = [np.argmax(i) for i in result] return result_label def test (self, model_path, data, label ): model = self.load_model_fromfile(model_path) loss, acc = model.evaluate(data, label) return loss, acc
加载数据 在我们用其他方式处理完数据之后,我们拿到了我们想要的格式,但是这个格式并不是可以直接被模型接受的,因此我们需要加载数据,并且进行一些处理,比如编码或者 padding.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class DataSet : def __init__ (self, data_path, labels ): with open (data_path, "rb" ) as f: self.data = f.read().decode("utf-8" ) self.process_data = self.process_data() self.labels = labels def process_data (self ): train_data = self.data.split("\n\n" ) train_data = [token.split("\n" ) for token in train_data] train_data = [[j.split() for j in i] for i in train_data] train_data.pop() return train_data def generate_data (self, vocab, maxlen ): char_data_sen = [[token[0 ] for token in i] for i in self.process_data] label_sen = [[token[1 ] for token in i] for i in self.process_data] sen2id = [[vocab.get(char, 0 ) for char in sen] for sen in char_data_sen] label2id = {label: id_ for id_, label in enumerate (self.labels)} lab_sen2id = [[label2id.get(lab, 0 ) for lab in sen] for sen in label_sen] sen_pad = pad_sequences(sen2id, maxlen) lab_pad = pad_sequences(lab_sen2id, maxlen, value=-1 ) lab_pad = np.expand_dims(lab_pad, 2 ) return sen_pad, lab_pad
进行完上线的三个步骤之后,我们基本上就可以进行训练了。
还有一部分的功能性代码,比如启动参数,模型保存格式等没有贴出来,使用的时候可以直接从 github 上看一下就好。
在** python3, keras 2.2.4** 环境下,执行 python3 model.py --mode=train, 即可开始训练,会将模型自动保存到* model 路径下,保存为 H5 和 SavedModel *两种格式。
评估模型 模型运行期间及每一次 epoch 运行结束,会打印响应的 loss 及 accuracy. 如下图所示:
此外还可以运行python3 model.py --mode=predict --input_model_dir=model来进行交互式的预测。
在线预测 离线训练得到了效果让我们满意的模型之后,就是在线预测的流程了。
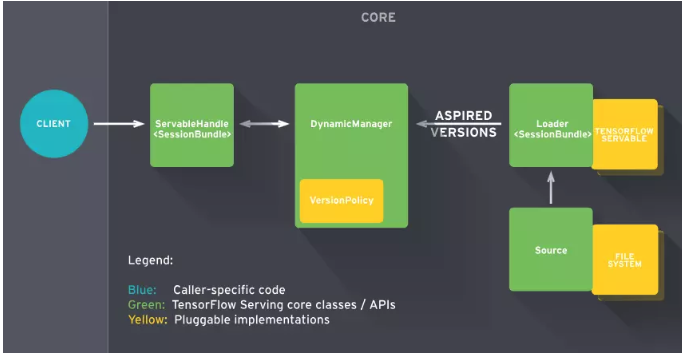
tensorflow 模型如何部署到线上,一直是比较花里胡哨的,针对这种情况 Google 提供了 TensorFlow Servering,可以用一套标准化的流程,将训练好的模型直接上线并提供服务。
tensorflow serving 介绍 TensorFlow Serving 是一个用于机器学习模型 serving 的高性能开源库。它可以将训练好的机器学习模型部署到线上,使用 gRPC 作为接口接受外部调用。它支持模型热更新与自动模型版本管理。这意味着一旦部署 TensorFlow Serving 后,不再需要为线上服务操心,只需要关心你的线下模型训练。
tensorflow serving 持续集成的大概流程如下:
基于 TF Serving 的持续集成框架还是挺简明的,基本分三个步骤:
离线模型训练
模型上线
服务使用
TF Serving 工作流程如下:
模型保存格式 要想使用 tensorflow serving 来部署模型,需要将模型保存为特定的格式。
如果你是使用 **keras models **构建的模型,那么直接tf.saved_model.save(self.model, save_dir)即可。
如果你是使用 keras sequential 构建的模型,那么使用下面的方法,可以让你将序列模型保存为** SavedModel **格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def export_saved_model (self, saved_dir, epoch ): model_version = epoch model_signature = tf.saved_model.signature_def_utils.predict_signature_def( inputs={'input' : self.model.input }, outputs={'output' : self.model.output}) export_path = os.path.join(compat.as_bytes(saved_dir), compat.as_bytes(str (model_version))) builder = tf.saved_model.builder.SavedModelBuilder(export_path) builder.add_meta_graph_and_variables( sess=K.get_session(), tags=[tf.saved_model.tag_constants.SERVING], clear_devices=True , signature_def_map={ tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY: model_signature }) builder.save()
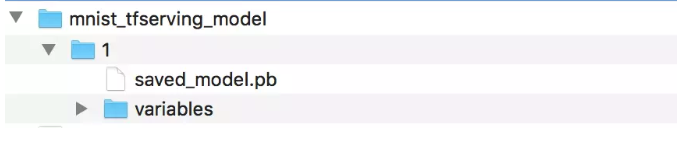
加载模型 将训练完毕的模型放到 serving 下对应的目录,让 serving 进行加载,模型文件树应该如下:
我在服务端启动 serving 的时候,使用了如下命令:
1 2 3 4 5 6 cmd="./tensorflow_model_server \ --port=4590 \ --rest_api_port=4591 \ --model_config_file=model/ \ --tensorflow_session_parallelism=40 \ --per_process_gpu_memory_fraction=0.2"
意味着我读取当前目录下 model 文件夹下的模型,加载并且对外提供了 RESTFUL 服务(在 4590 端口)以及 grpc 服务(在 4591 端口).
客户端请求 serving 对外提供了 RESTFUL 接口以及 GRPC 接口,足够我们使用了。
RESTFUL
在命令行执行curl -d '{"inputs": [[348.0,3848.0,2557]]}' -X POST http://localhost:4591/v1/models/model:predict, 其中,inputs 是在输出模型时定义的模型输入数据。也就是模型签名。
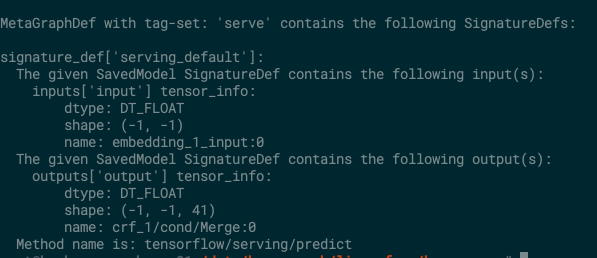
如果不确定自己的模型定义,可以使用 tensorflow 自带的saved_model_cli.py文件来查看,首先运行find / -name="saved_model_cli.py", 找到本机上的对应文件,如果没有,可以去下载 TensorFlow 的源码,其中包括这个文件。
然后执行 python saved_model_cli.py show --dir model/15 --all, 就可以看到下面这样的输出。
我的模型定义了:
名为”input”的输入,是一个二维的矩阵。
名为”output”的输出,是一个三维的矩阵。
模型返回的预测结果为一个三维数据,其中每一个数组代表一个字符所在的标签。
以 “王强” 为例。
得到的结果为 shapre=(1,2,7) 的数组,其中 1 指的是我们只输入了一个句子,2 指的是句子的长度,7 指的是我们所有 tag 的长度。
1 2 3 4 [ [0,1,0,0,0,0,0] [0,0,1,0,0,0,0] ]
标签顺序是:[O, B-PER, I-PER, B-LOC, I-LOC, B-ORG, I-ORG]
用1所在的下标对应到标签中,可以发现王强的结果是B-PER, I-PER , 也就是一个人名。
grpc
输入输出和 RESTFUL 是一样的,只是方式可能有点不一样,这里简单的贴一下集成 GRPC 的那块代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public static void main (String[] args) { ManagedChannel channel = ManagedChannelBuilder.forAddress("192.168.1.251" , 7010 ).usePlaintext(true ).build(); PredictionServiceGrpc.PredictionServiceBlockingStub stub = PredictionServiceGrpc.newBlockingStub(channel); Predict.PredictRequest.Builder predictRequestBuilder = Predict.PredictRequest.newBuilder(); Model.ModelSpec.Builder modelSpecBuilder = Model.ModelSpec.newBuilder(); modelSpecBuilder.setName("model" ); modelSpecBuilder.setSignatureName("" ); predictRequestBuilder.setModelSpec(modelSpecBuilder); TensorProto.Builder tensorProtoBuilder = TensorProto.newBuilder(); tensorProtoBuilder.setDtype(DataType.DT_FLOAT); TensorShapeProto.Builder tensorShapeBuilder = TensorShapeProto.newBuilder(); tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(1 )); tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(3 )); String s = "呼延十" ; List<Float> ret = new ArrayList <>(); ret.add(348.0f ); ret.add(3848.0f ); ret.add(2557.0f ); tensorProtoBuilder.setTensorShape(tensorShapeBuilder.build()); tensorProtoBuilder.addAllFloatVal(ret); predictRequestBuilder.putInputs("input" , tensorProtoBuilder.build()); Predict.PredictResponse predictResponse = stub.predict(predictRequestBuilder.build()); List<Float> output = predictResponse.getOutputsMap().get("output" ).getFloatValList(); List<String> tags = Arrays.asList("O" , "B-PER" , "I-PER" , "B-LOC" , "I-LOC" , "B-ORG" , "i-ORG" ); List<String> rets = phraseFrom(s, output, tags); System.out.println(rets); } private static List<String> phraseFrom (String q, List<Float> output, List<String> tags) { List<List<Float>> partition = Lists.partition(output, tags.size()); List<Integer> idx = new ArrayList <>(); for (List<Float> floats : partition) { for (int j = 0 ; j < floats.size(); j++) { if (floats.get(j) == 1.0f ) { idx.add(j); break ; } } } assert q.length() != idx.size(); StringBuilder sb = new StringBuilder (); char [] chars = q.toCharArray(); List<String> rets = new ArrayList <>(); for (int i = 0 ; i < chars.length; i++) { Integer tag = idx.get(i); if ((tag & 1 ) == 1 && sb.length() != 0 ) { String item = sb.toString(); String ret = tags.get(idx.get(i - 1 )); rets.add(ret); sb.setLength(0 ); sb.append(chars[i]); } else { sb.append(chars[i]); } } if (sb.length() != 0 ) { String ret = tags.get(idx.get(q.length() - 1 )); rets.add(ret); } return rets; }
效果 项目开发完成后,模型预测正确率 97%(训练了 30 个 epoch), 线上预测与 TensorFlow serving 交互耗时 20ms.
运行环境 python 3.6.4
相关链接 Bidirectional LSTM-CRF Models for Sequence Tagging
tensorflow serving 官网
bilstm-crf with tensorflow
bilstm-crf with keras
完。
ChangeLog
2019-11-227 完成
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

 .
.