前言
这篇文章介绍。fdx 文件格式。
.fdx 文件整体格式
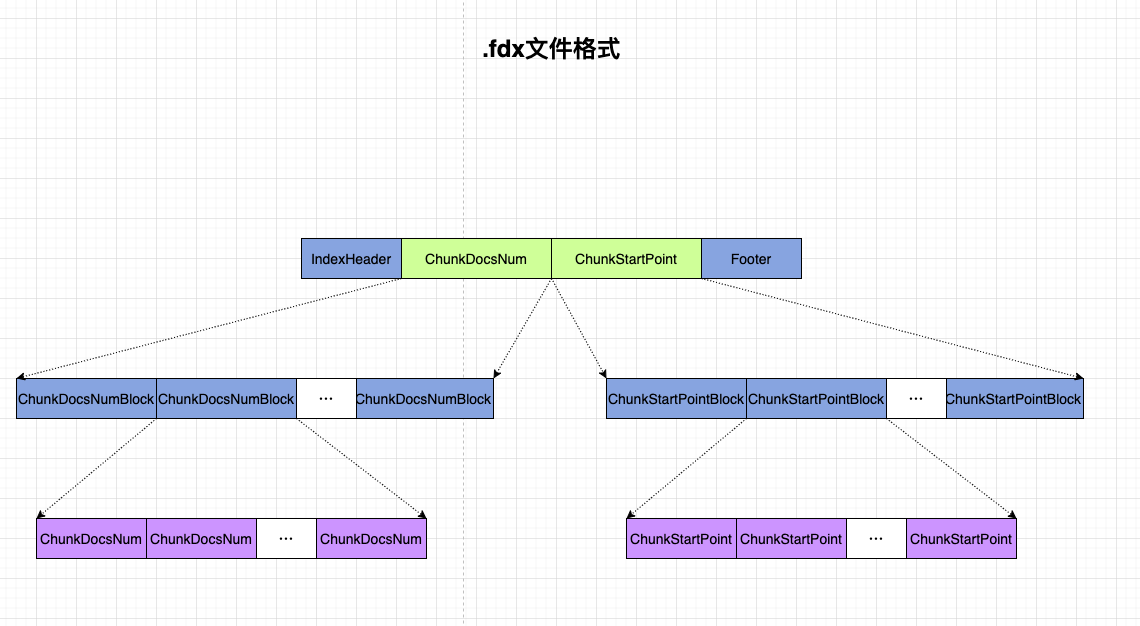
看起来比较简单,实际写入代码是 fdt,fdm,fdx 三个文件中最复杂的。
其中内容包括:
- IndexHeader. 索引文件头,前面说过,就不细说了。
- Footer: 索引文件脚,不细说。
- ChunkDocsNum: 一个数组,含义是:每个 Chunk 中的 doc 数量。
- ChunkStartPoint: 一个数组,含义是:每个 chunk 的内容在 fdt 文件中文件地址。
鉴于存储方式比较复杂,我们就直接快进到源代码。
写入代码分析
在CompressingStoredFieldsWriter类的构造函数中,初始化了FieldsIndexWriter类的实例,由它来进行 fdx 文件的写入,看看他的构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| FieldsIndexWriter(Directory dir, String name, String suffix, String extension,
String codecName, byte[] id, int blockShift, IOContext ioContext) throws IOException {
this.dir = dir;
this.name = name;
this.suffix = suffix;
this.extension = extension;
this.codecName = codecName;
this.id = id;
this.blockShift = blockShift;
this.ioContext = ioContext;
this.docsOut = dir.createTempOutput(name, codecName + "-doc_ids", ioContext);
boolean success = false;
try {
CodecUtil.writeHeader(docsOut, codecName + "Docs", VERSION_CURRENT);
filePointersOut = dir.createTempOutput(name, codecName + "file_pointers", ioContext);
CodecUtil.writeHeader(filePointersOut, codecName + "FilePointers", VERSION_CURRENT);
success = true;
} finally {
if (success == false) {
close();
}
}
}
|
在构造函数中,没有创建 fdx 文件,而是创建了两个临时文件,docsOut和filePointOut. 分别用于存储前面提到的两份数据。每个 Chunk 中的 doc 数量及每个 chunk 的内容在 fdt 文件中文件地址.
之后,每次向 fdt 文件中,写入一个 chunk 的内容,同时会调用下方的方法,写入当前 chunk 的 doc 数量,及 fdt 文件地址。注意写入的是临时文件。
1
2
3
4
5
6
7
8
9
10
| void writeIndex(int numDocs, long startPointer) throws IOException {
assert startPointer >= previousFP;
docsOut.writeVInt(numDocs);
filePointersOut.writeVLong(startPointer - previousFP);
previousFP = startPointer;
totalDocs += numDocs;
totalChunks++;
}
|
在所有数据写入完成后,会调用FieldsIndexWriter类的 finish 方法,来进行生成真正的 fdx 文件。该方法比较复杂,让我们一步步捋一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
|
void finish(int numDocs, long maxPointer, IndexOutput metaOut) throws IOException {
if (numDocs != totalDocs) {
throw new IllegalStateException("Expected " + numDocs + " docs, but got " + totalDocs);
}
CodecUtil.writeFooter(docsOut);
CodecUtil.writeFooter(filePointersOut);
IOUtils.close(docsOut, filePointersOut);
try (IndexOutput dataOut = dir.createOutput(IndexFileNames.segmentFileName(name, suffix, extension), ioContext)) {
CodecUtil.writeIndexHeader(dataOut, codecName + "Idx", VERSION_CURRENT, id, suffix);
metaOut.writeInt(numDocs);
metaOut.writeInt(blockShift);
metaOut.writeInt(totalChunks + 1);
long filePointer = dataOut.getFilePointer();
metaOut.writeLong(filePointer);
try (ChecksumIndexInput docsIn = dir.openChecksumInput(docsOut.getName(), IOContext.READONCE)) {
CodecUtil.checkHeader(docsIn, codecName + "Docs", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter docs = DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long doc = 0;
docs.add(doc);
for (int i = 0; i < totalChunks; ++i) {
doc += docsIn.readVInt();
docs.add(doc);
}
docs.finish();
if (doc != totalDocs) {
throw new CorruptIndexException("Docs don't add up", docsIn);
}
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(docsIn, priorE);
}
}
dir.deleteFile(docsOut.getName());
docsOut = null;
long filePointer1 = dataOut.getFilePointer();
metaOut.writeLong(filePointer1);
try (ChecksumIndexInput filePointersIn = dir.openChecksumInput(filePointersOut.getName(), IOContext.READONCE)) {
CodecUtil.checkHeader(filePointersIn, codecName + "FilePointers", VERSION_CURRENT, VERSION_CURRENT);
Throwable priorE = null;
try {
final DirectMonotonicWriter filePointers = DirectMonotonicWriter.getInstance(metaOut, dataOut, totalChunks + 1, blockShift);
long fp = 0;
for (int i = 0; i < totalChunks; ++i) {
fp += filePointersIn.readVLong();
filePointers.add(fp);
}
if (maxPointer < fp) {
throw new CorruptIndexException("File pointers don't add up", filePointersIn);
}
filePointers.add(maxPointer);
filePointers.finish();
} catch (Throwable e) {
priorE = e;
} finally {
CodecUtil.checkFooter(filePointersIn, priorE);
}
}
dir.deleteFile(filePointersOut.getName());
filePointersOut = null;
long filePointer2 = dataOut.getFilePointer();
metaOut.writeLong(filePointer2);
metaOut.writeLong(maxPointer);
CodecUtil.writeFooter(dataOut);
}
}
|
需要注意,此时所有的 field 数据已经写入。进行文件的转换操作而已。
- 向两个临时文件写入 Footer, 之后将其关闭。
- 打开真正的 fdx 文件,写入 Header.
- 向之前介绍过的 fdm 文件中,写入部分元数据。不是这篇文章重点,就不详细解释了。
- 打开刚才的临时文件
DocsOut, 把数据读出来。使用DirectMonotonicWriter来将数据写入 fdx 文件。对DirectMonotonicWriter类不熟悉的话,可以阅读 DirectMonotonicWriter 源码解析. 之后将 Docs 的临时文件删除。
- 打开刚才的临时文件
filePointOut, 把数据读出来,调用DirectMonotonicWriter进行写入 fdx 文件。之后将临时文件删除。
- 向 fdx 文件写入 Footer. 关闭文件。
如何索引?
从名字上可以看出来,fdx 文件是用来作为 fdt 文件的索引的。作用就是:能够方便快速查询到指定的 doc 的 field 信息。
那么它是如何作为索引的呢,三个 field 相关文件的对应关系是怎样的。
以下内容为猜想内容,如果你看到这条红字,不要相信。未来的某一天,我看到代码且确认了下面的内容,我会回来删掉这行红字。
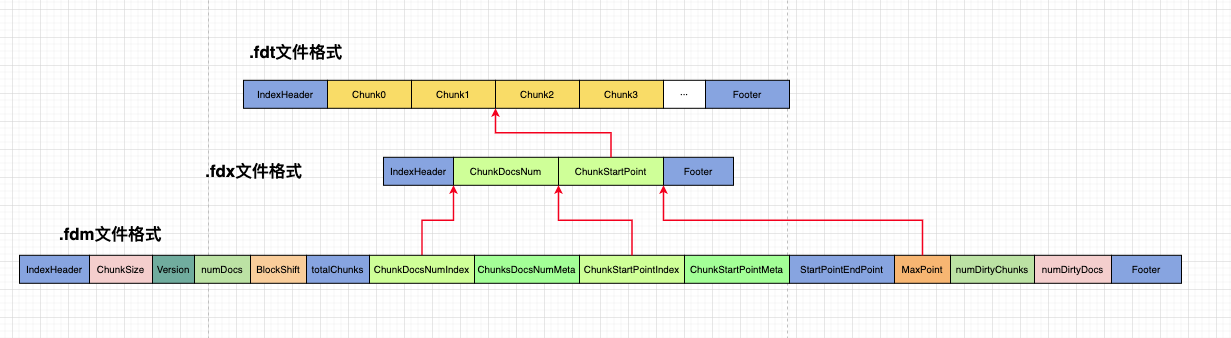
当我们拿到一个 DocId, 该如何通过这三个文件拿到该 doc 的具体 field 信息呢?
首先,fdx 及 fdm 文件都比较小,可以全部加载到内存中。
- 根据 fdm 中的 ChunkDocsNumIndex, 可以找到在 fdx 文件中,存储 Chunk 中 doc 数量的起始文件地址。
- 读出每个 Chunk 的 doc 数量,用 docId, 即可以算出 该 DocId 位于第几个 Chunk 的第几个 Doc.
- 根据 fdx 文件中 ChunkDocsNum 和 ChunkStartPoint 文件时平行数据的关系,即可以求出,DocId 所在的 chunk, 其 field 信息在 fdt 文件中的起始文件位置。
- 将 fdt 文件中,该 chunk 的数据读入,即可获取到给定 DocId 的具体内容。
不用完整的遍历 fdt 文件,而是通过 fdx 及 fdm 做了一些索引操作。比较高效。
总结
fdx 文件中,主要是存储以 chunk 为单位的 doc 数量,对应 chunk 在 fdt 文件中的起始位置。由这些数据可以对 fdt 文件进行随机方法而不用顺序访问,加快了读取速度。
为了对 fdx 文件中的数据进行压缩,防止读取到内存中过大,需要 fdm 进行一些配合存储。通过DirectMonotonicWriter进行压缩写入。
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。

以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

