本文使用Lucene代码版本: 8.7.0
前言
本文学习一下.fnm文件的格式与内容。
fnm文件主要存储域的基础信息,前面我们知道了,在fdt,fdm,fdx三个文件中,配合存储了域的值信息,其中在fdt文件中,存储域的值信息时,为了将每个值与域名能对应起来,存储了FieldNumberAndType. 详情可查看 [lucene索引文件之fdt文件]http://huyan.couplecoders.tech/lucene/%E6%90%9C%E7%B4%A2%EF%BC%8C%E7%B4%A2%E5%BC%95%E6%96%87%E4%BB%B6/2021/01/04/lucene%E7%B3%BB%E5%88%97(%E5%85%AD)%E7%B4%A2%E5%BC%95%E6%A0%BC%E5%BC%8F%E4%B9%8Bfdt%E6%96%87%E4%BB%B6/)
众所周知,只有number不足以描述一个域的基础信息,至少要知道个名字吧?Number不足以描述,但是足以对应。
对应的就是在fnm文件中存储的详细信息咯。
.fnm文件整体结构
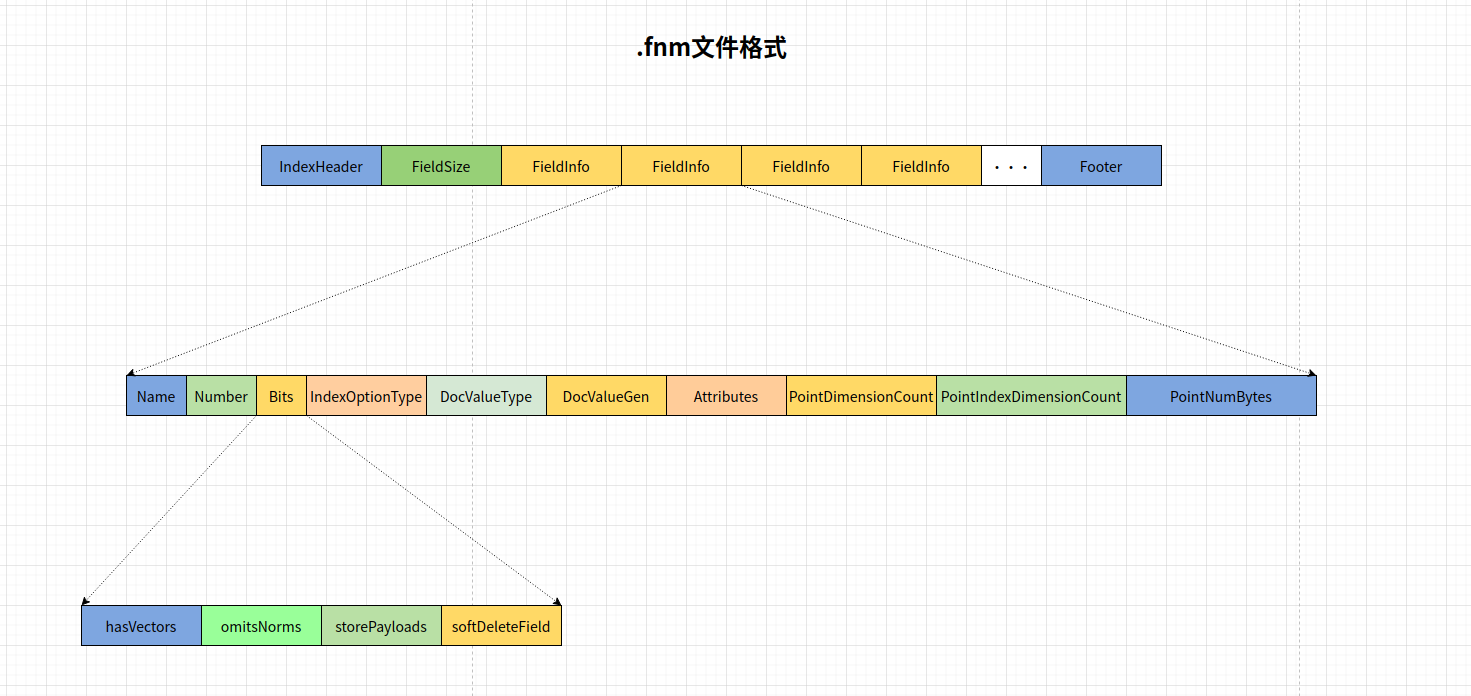
其中包括:
- FieldSize: 以变长int存储的field总数
- Name: field的名字,string格式
- Number: field的编号,变长int
- Bits: 以bit的形式,存储了4个布尔变量,分别为:
4.1 hasVectors: 是否有向量的
4.2: omitNorms: 是否有忽略归一化的
4.3 storePayloads: 未知
4.4: softDeleteField: 是否软删除 - IndexOptionType: 索引选项类型
- DocValueType: docValue存储的类型
- DocValueGen: DocValue迭代次数
- Attributes: 一些属性值
- PointDimensionCount: 当filed是point类型时,记录的一些字段
- PointIndexDimensionCount: 当filed是point类型时,记录的一些字段
- PointNumBytes: 当filed是point类型时,记录的一些字段
这个文件有个特殊的地方,就是写入部分及其简单,几十行就写完了,但是涉及到的属性比较多,我也没有搞清楚所有字段的作用,因此会有部分未知,等待补充。
直接快进到代码分析。
相关写入代码分析
在8.7.0版本的默认配置下,对于域基础信息的编码,使用的是org.apache.lucene.codecs.lucene60.Lucene60FieldInfosFormat类.
他比较简单,只有read方法和write方法,其中前者负责从磁盘读取某一个分片的所有域信息,后者负责将内存中的域信息写入文件。
Write方法
1 |
|
比较简单,做了以下几个步骤:
- 写入Header
- 写入域的总数
- 遍历所有的域,按照图中的顺序,逐一写入所有的字段
- 写入Footer.
结语
这篇文章显得很水,但是其实看了蛮久,想力图看懂每一个字段的作用,生成方法等全部内容。
但是写的时候发现,这篇文章,应该是简单介绍fnm文件中,存储了什么内容,怎么编码,让人能够逐字节的读懂fnm文件。知道每一个字节的内容是哪个字段。
至于字段的含义及计算方法,却应该在索引过程之类的地方讲述,否则就打破了文件格式与索引过程之间的边界。
边界很重要。
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十

