本文使用Lucene代码版本: 8.7.0
前言
本文学习一下.doc文件的格式与内容。
doc文件中存储了每个term对应的所有docId,及词频信息.
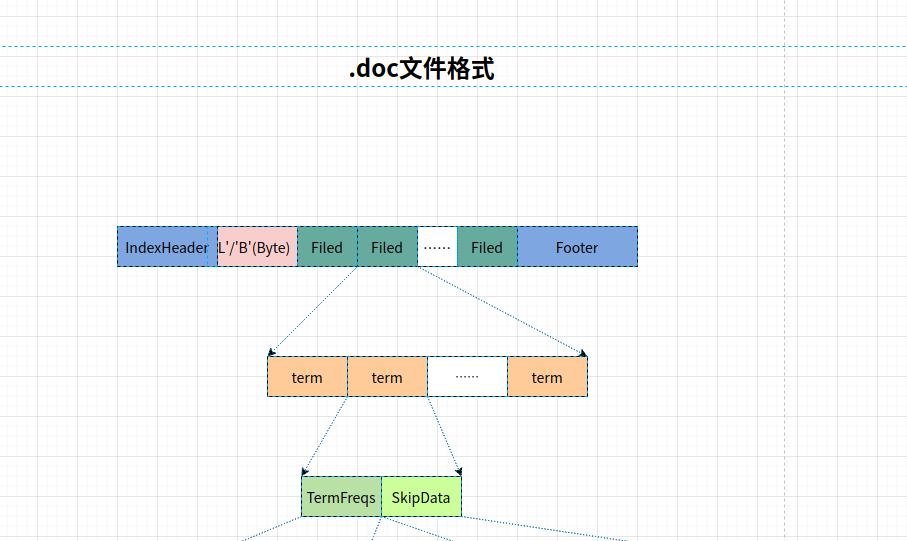
.doc文件整体结构
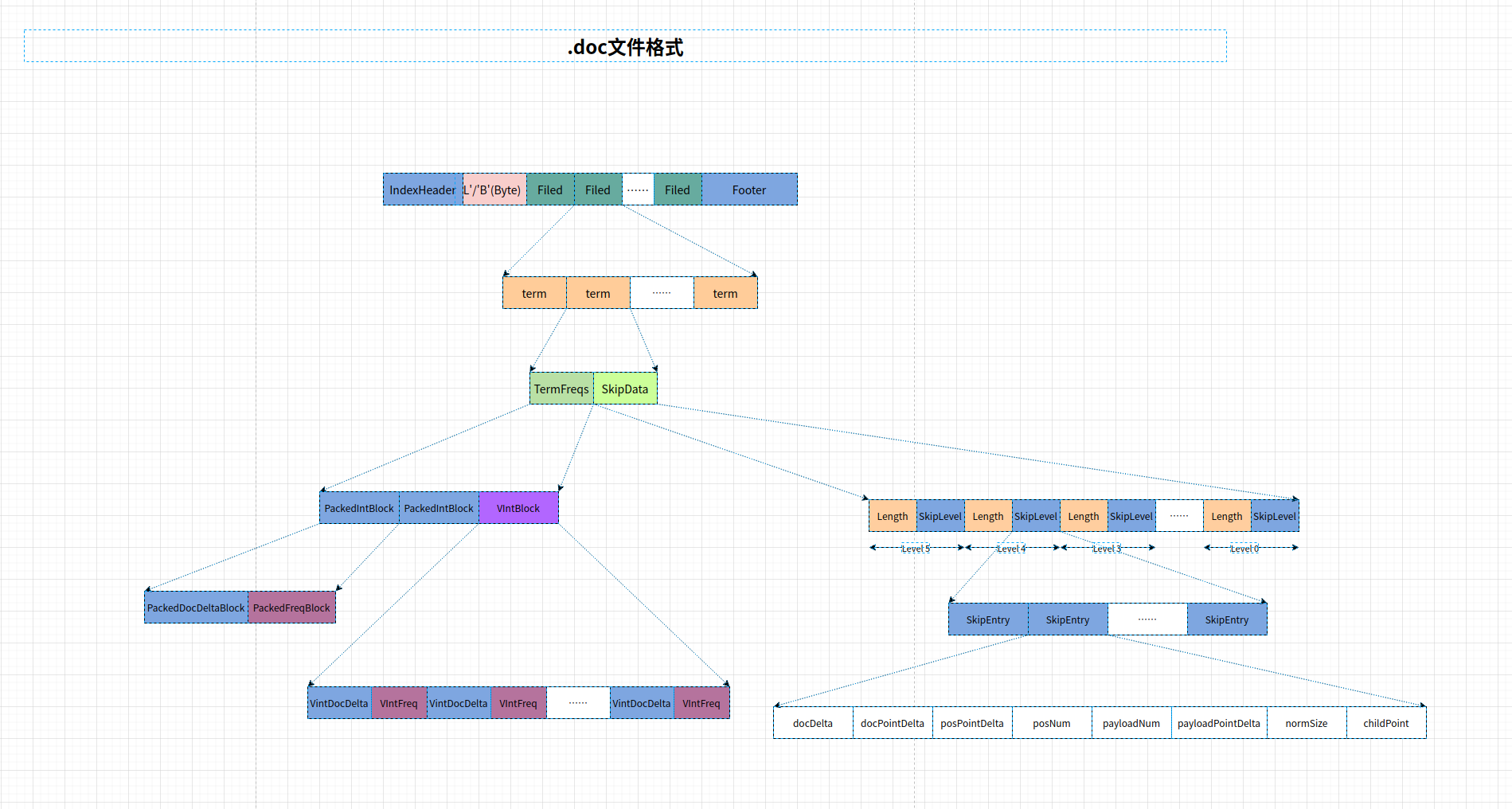
图片好像有点大,看不清,分块的图片放在文章最后
其中的字段解释:
- IndexHeader: 索引头
- ‘L’/‘B’: ByteOrder是Big_ENDIAN还是Little_ENDIAN.
- Field: 一个field的所有term的信息.
- Footer: 索引尾.
- Filed: 某个域的所有信息
- Term: 某个Term的所有信息
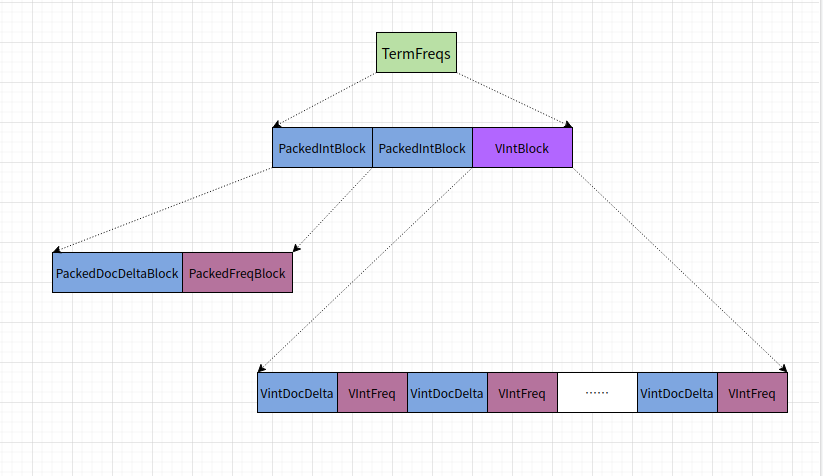
- TermFreqs: 当前term的docId信息及词频信息.
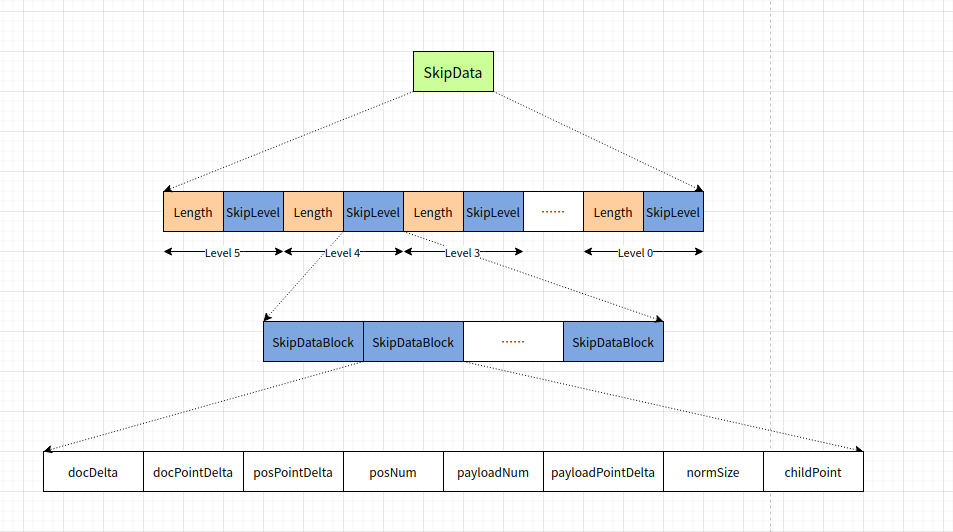
- SkipData: 当前term的跳表信息,可以用来快速读取termFreqs。
- PackedIntBlock 一整个块(128个Doc)的信息,使用PackedInt进行编码
- VintBlock 最后剩下的不满的一个块,使用VInt进行编码.
- PackedDocDeltaBlock: docId的增量编码,每128个使用PackedInt进行编码,可以通过增量编码最终复现所有DocId.
- PackedDocFreqBlock: 与上面对应的词频信息编码。
- VIntDocDelta: docId增量编码的变长Int编码,在最后一个不一定够128个的块中,所有值使用变长int编码.
- VIntFreq: 与上面对应的词频编码。
- length: 跳表当前层信息的长度,用来读取的时候分层
- SkipLevel: 跳表的某一层的信息
- SkipEntry: 在TermFreqs中,每次写入一个128个Doc的block。需要写入对应的跳跃节点信息.
- DocDelta: 当前跳跃点与上一个跳跃点的docId的增量编码.
- DocPointerDelta: 存储对应block具体信息的文件位置,也采用了增量编码.
- posPointDelta: 存储对应block的位置信息的文件位置,即.pos文件中的位置,也采用了增量编码。
- posNum: 存储了位置信息的数量
- payloadNum: 存储了payload的数量
- payloadPonitDelta: 存储对应block的有效载荷信息的文件位置,即.pay文件中的位置,也采用了增量编码.
- normSize: term归一化后的大小
- childPoint: 如果当前层不是第0层,这里存储了当前跳跃点对应到下一层的位置.
各种东西还是比较多的, 具体的信息留在索引过程分析中再讲,我们快进到写入代码分析.
相关写入代码分析
在org.apache.lucene.codecs.lucene84.Lucene84PostingsWriter#Lucene84PostingsWriter中,对doc文件进行了初始化,及写入了IndexHeader,以及代表字节顺序的L/B.
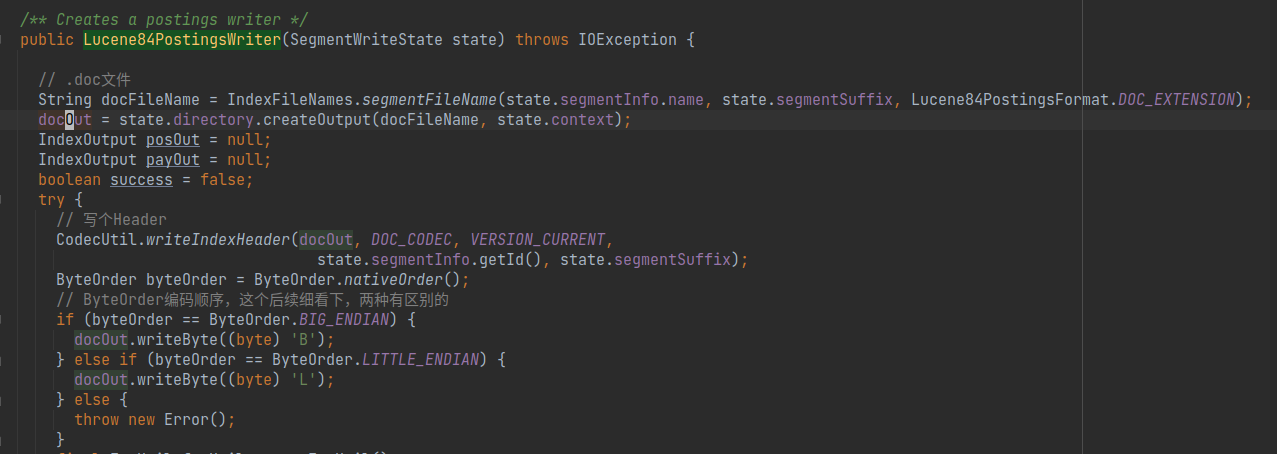
在org.apache.lucene.codecs.lucene84.Lucene84PostingsWriter#startDoc中进行了PackedIntBlock的写入,
如果当前buffer已满,即128个doc信息已经缓冲,则进行一次编码写入.
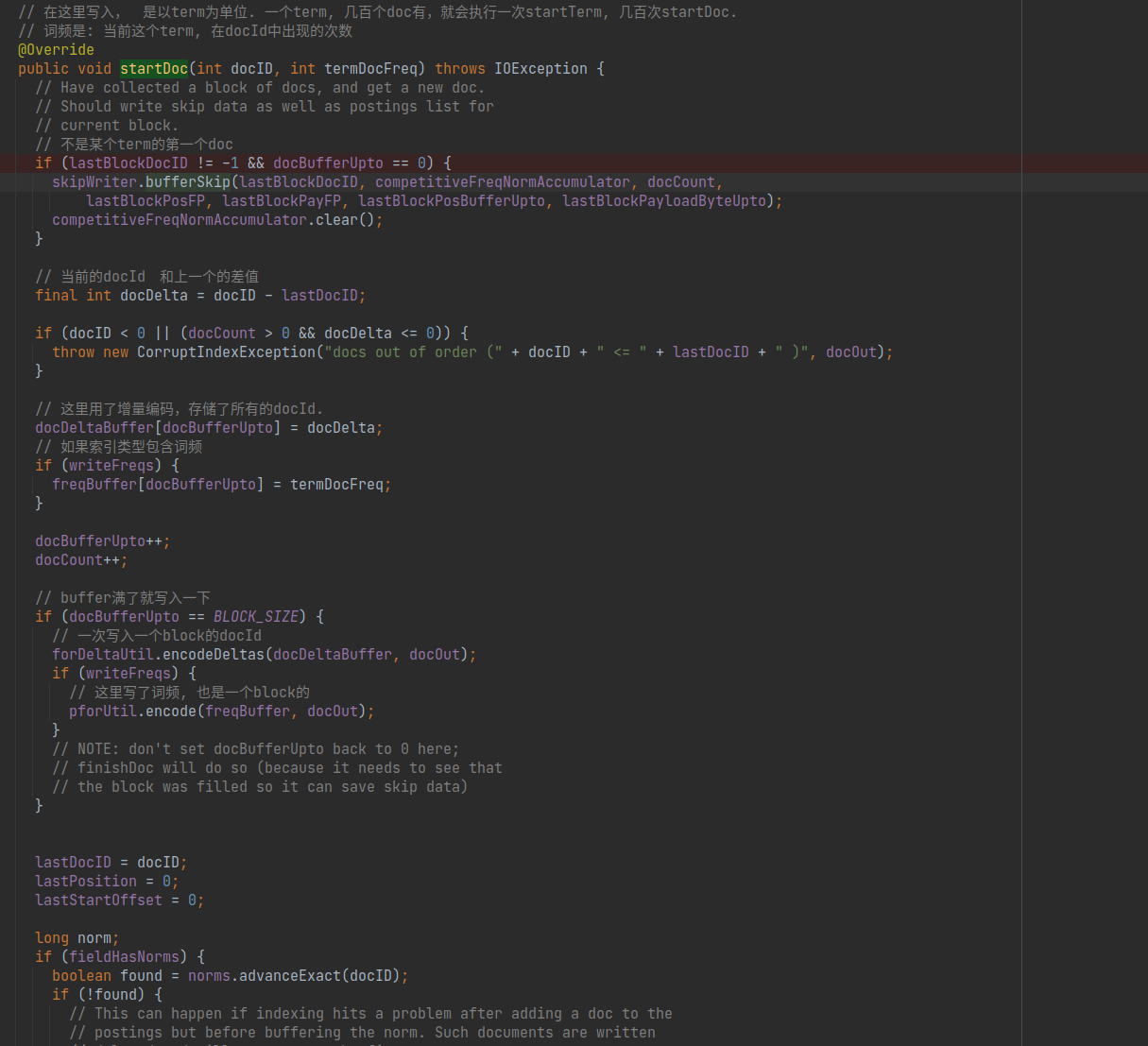
在这段代码中,与本文相关的有两个部分.
- 如果当前doc,不是term的第一个block,但是后面的block中的第一个doc. 那么就进行一次跳跃节点的缓冲操作.
- 如果当前buffer满了,则进行一次写入操作,调用
ForDeltaUtil和PForUtil的encode方法,对128个long值进行编码及写入.
在org.apache.lucene.codecs.lucene84.Lucene84PostingsWriter#finishTerm中,如果此时内存中还有不足128个doc信息,不够进行一次PackedInt的写入,那么就使用变长int编码,直接将剩余的doc信息写入。
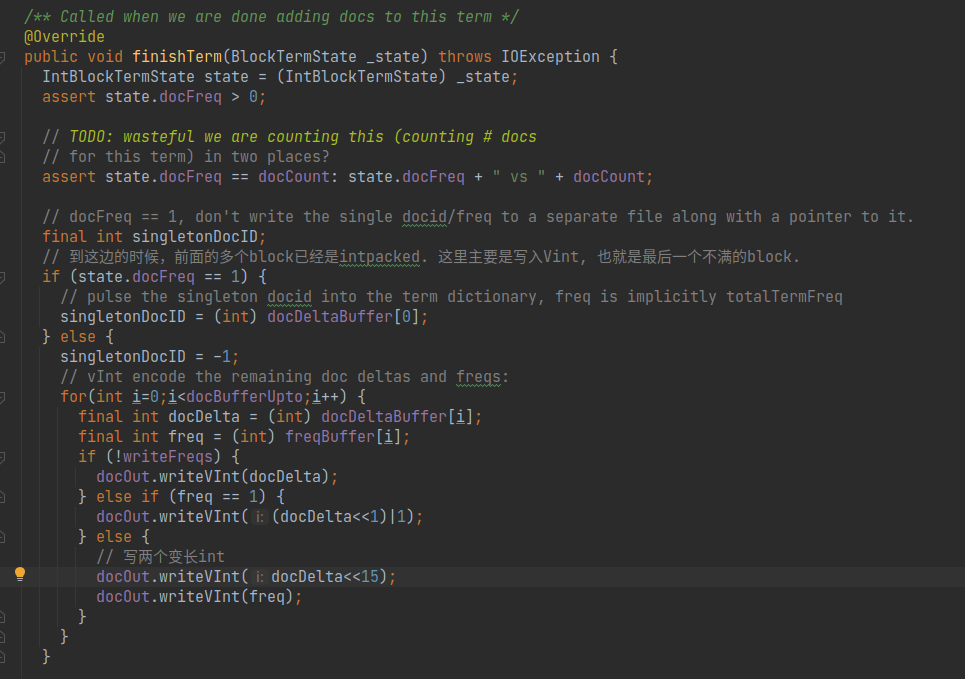
在写入完成之后,当前term的docId,词频,位置信息,有效载荷信息等已经完成了写入, 此时执行下面的方法,进行跳跃节点的写入。
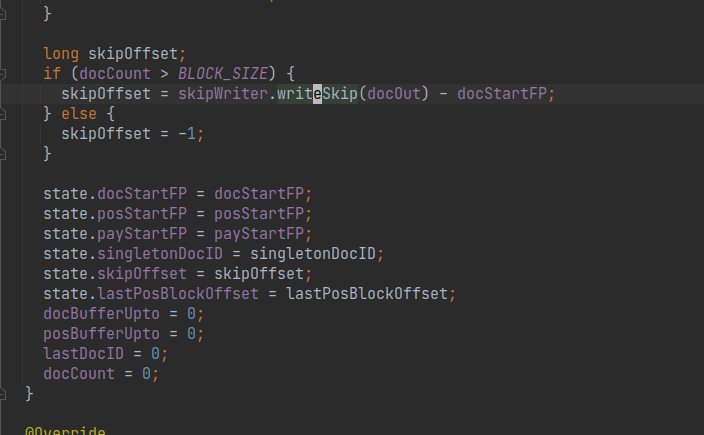
org.apache.lucene.codecs.MultiLevelSkipListWriter#writeSkip 方法比较简单,对每一个跳跃表的层,先写长度,再写内容即可.
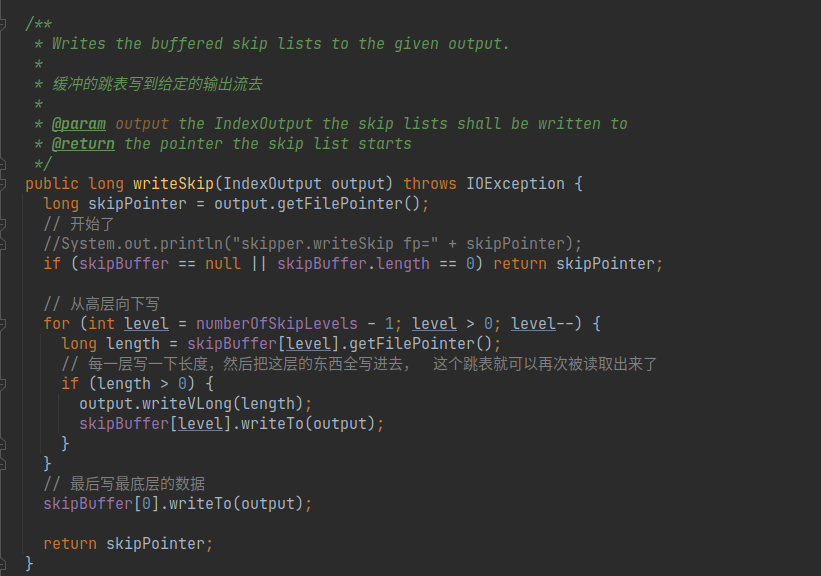
对于跳跃节点的信息生成,如前面所说,在每一个term的除了第一个block, 其他所有block的第一个doc开始处理前,会调用org.apache.lucene.codecs.lucene84.Lucene84SkipWriter#writeSkipData 来进行跳跃节点的信息写入.
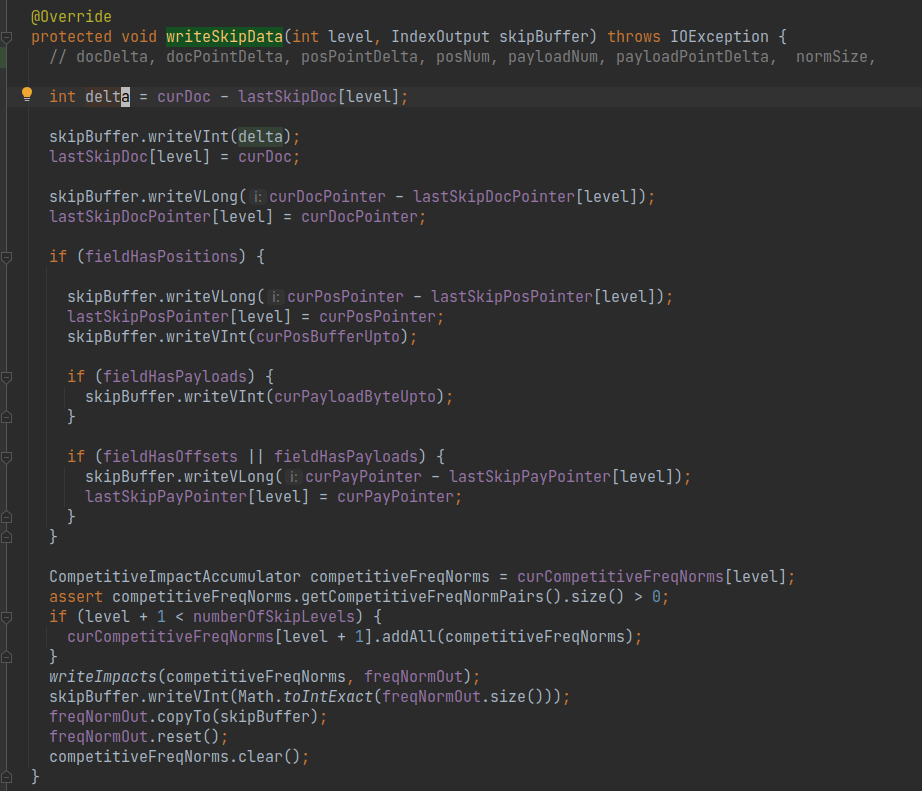
在该方法中,以变长Int的方式,存储了需要的多个字段信息,比如docId增量,.doc,.pos,.pay文件位置的增量编码等等,在读取时可以根据跳表节点中的各种文件位置,快速的定位相关元素及其附加信息.
结语
这篇文章又是耗时巨久…主要原因在于看倒排信息的生成部分,看蒙了,因此耽误了许久.
简单的讲了下.doc文件中,都存储了什么,以什么顺序存储,以什么编码存储。而对于其中相关信息的生成及计算方式,并不涉及.
参考文章
https://www.amazingkoala.com.cn/Lucene/suoyinwenjian/2019/0324/42.html
这是一个对lucene颇有研究的博主的博客,各位如有兴趣,可以直接浏览他的文章,也许你会发现我的图和他的图非常像.
但是确实不是有心抄袭,而是我学习了博主的文章之后,怎么画图都有点像,也没有什么办法. 博主对于lucene理解比较清晰,但是文章十分简洁,大家互相参考着看,可能更有利于理解.
图片分块
整体图
TermFreqs模块
SkipData模块
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 <呼延十 >——>呼延十

