前言
Lucene 中对于选择算法,有两个实现,快速选择和基数选择.
上一篇文章讲了IntroSelector,这篇文章讲RadixSelector.
基数排序介绍
基数选择和基数排序非常类似,本文侧重点在于 Lucene 的实现,因此对于基数排序的详细原理就不解释了。
大概介绍下:
基数排序(英语:Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。基数排序的发明可以追溯到 1887 年赫尔曼·何乐礼在打孔卡片制表机(Tabulation Machine)上的贡献 [1]。
它是这样实现的:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序的方式可以采用 LSD(Least significant digital)或 MSD(Most significant digital),LSD 的排序方式由键值的最右边开始,而 MSD 则相反,由键值的最左边开始。
实现原理的话比较好懂。快进到 Lucene 的代码。
org.apache.lucene.util.RadixSelector 源码分析
版本 8.7.0
带有注释的完整源码在:org.apache.lucene.util.RadixSelector 源码分析
因为org.apache.lucene.util.RadixSelector也是对Selector的实现,那么他的入口函数也是 select. 我们从 select 开始分析。
入口 select 方法
1 |
|
可以看到,实现自接口的select方法只是简单的做了一个转发,之后进入重载的select方法。之后的逻辑就是一个条件语句。
如果to-from<100,或者递归层级大于 8 层, 就是用备选的选择算法(快速选择算法). 否则调用radixSelect.
以内部分为猜想,尚未证实
为什么要限制层数呢
这个问题我开始也百思不得其解。源码中对于这个的注释是:after that many levels of recursion we fall back to introselect anyway
this is used as a protection against the fact that radix sort performs worse when there are long common prefixes (probably because of cache locality)
我不明白为什么太长的公共前缀会导致性能变差,在实现时,我们完全可以直接跳过所有的公共前缀长度。
后来猜想,所谓的最坏情况,并不是所有元素都有一个很长的公共前缀,而是递增式的。
1 |
|
形如途中所示的数据,会导致 badcase.
- 当我们开始排序时,第一轮排序 a 全部一样,
- 第二轮是三个 b 和一个空。因此只有两个桶,一个桶是 1. 一个桶是 all -1. 相当于没怎么排序
- 第三轮和第二轮一样差劲。
这种情况就类似于快排里面的,每次都挑选到了最大的值。导致了最差劲的时间复杂度
但是对于快速选择算法,我们尚且有三者中位数法和中位数的中位数法来避免这一个问题,基数排序没有。因此只能设置阈值,当发现遇到了极端情况时,及时切换到快速选择算法上去。
radixSelect 方法
从方法的名字可以看出来,这是这个类的核心方法了。
流程图:
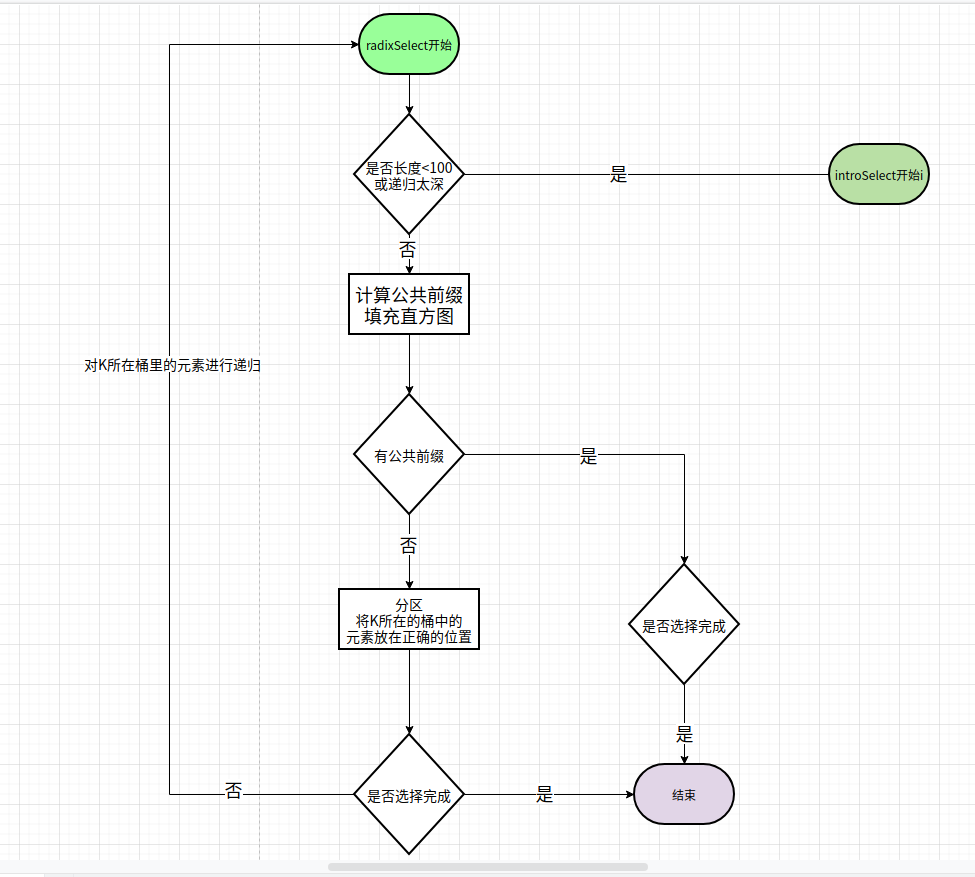
代码:
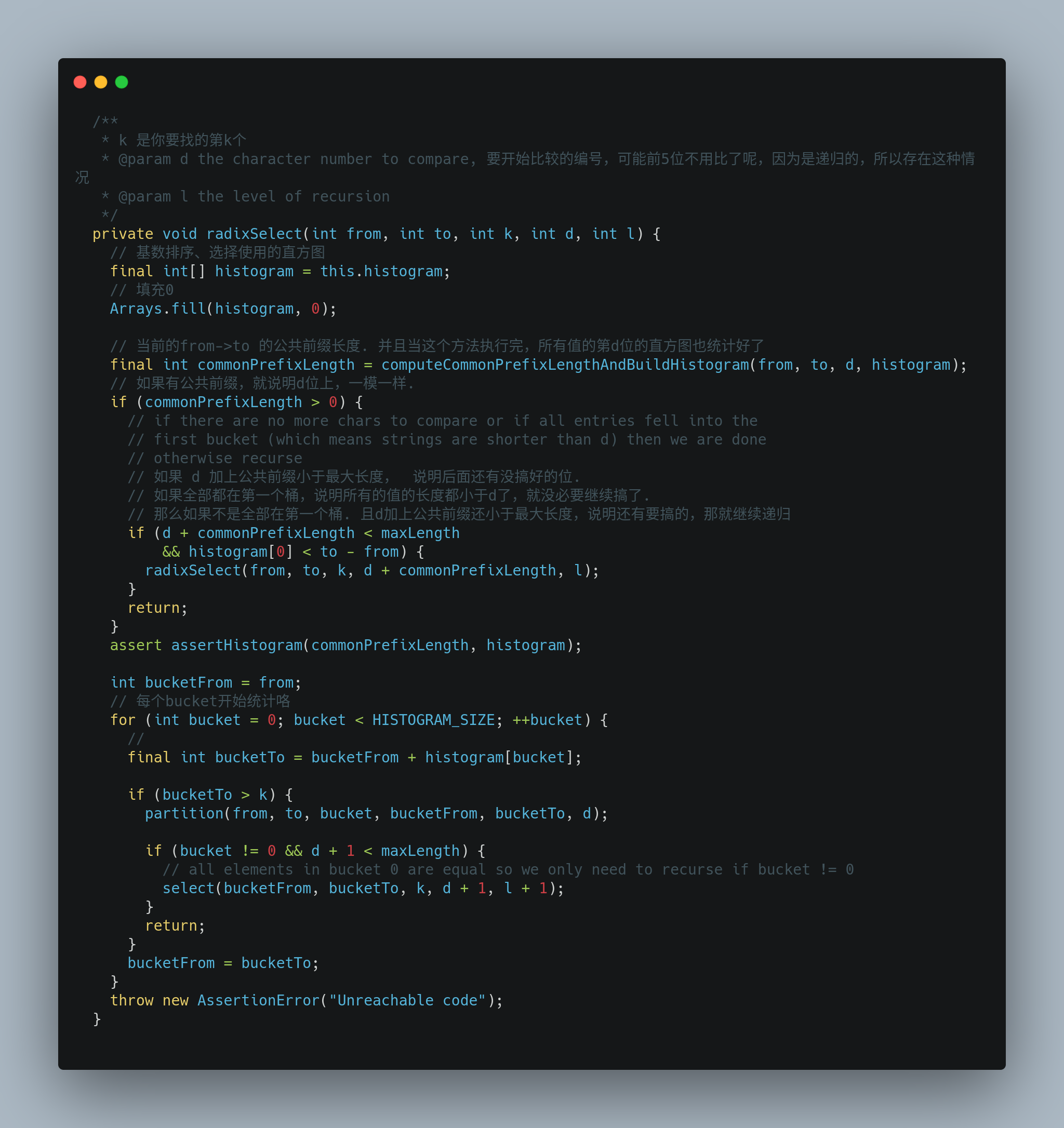
这个我看了好久。所以注释够多了。
核心流程:
- 计算公共前缀长度,构建当前字节的直方图
- 如果有公共前缀,则跳到该位进行计算
- 如果没有,则将直方图中 k 所在的桶进行递归运算。
就可以找到对应的第 K 位啦。
computeCommonPrefixLengthAndBuildHistogram 方法
这是另外一个值得一提的方法,它的功能是:
计算公共前缀,并填充直方图。
1 | /** Build a histogram of the number of values per {@link #getBucket(int, int) bucket} |
代码的核心路径是:
- 将第一个值全部放在公共前缀里面,此时公共前缀就是第一个值
- 从第二个开始遍历,逐个字节开始与第一个值进行比较,如果遇到不相等的值,减少公共前缀的长度
- 根据是否有公共前缀,构建第 K 字节上的值的直方图,一个字节最大值是 256. 加上一个 null 值,直方图共 257 位。
- 返回公共前缀和直方图。
第 1,2 步骤,就是一个标准的多个字符串求最长公共前缀的算法,与其刷题,不如看源码,到处都是原题呢~.
思考题
在org.apache.lucene.util.RadixSelector.select(int, int, int, int, int)方法中,
1 | private void select(int from, int to, int k, int d, int l) { |
比较递归最大深度的时候,使用的是d而不是l. 这是正确的吗?
从注释上看,l 才是递归的深度。
d 过大并不会影响效率,而且 d 最终一定会很大。
1
2aaaaaaaaaaac
aaaaaaaaaaab这两个字符串,我们通过一次求解就跳跃到了倒数第一位来进行比较,此时 d 已经大于 8 了。但是程序的时间复杂度很好。
这个值的错误,不会导致编译错误,或者程序结果错误。甚至都不会导致性能极度变差。
那么他导致的是什么呢?导致的是,很多本可以在基数选择的 O(3n) 的时间复杂度下解决的问题,被放到了快速选择的 O(5n) 下去解决。
导致的是平均的线性时间复杂度的常量变大了。
这是我的猜测,我也不知道对不对,还在思考哈哈哈哈。
思考题答案
经过一番思考,我确认了这就是个bug.在Jira上提交给官方后,提交patch修复了这个bug.
参考文章
https://zh.wikipedia.org/wiki/%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F
完。
联系我
最后,欢迎关注我的个人公众号【 呼延十 】,会不定期更新很多后端工程师的学习笔记。
也欢迎直接公众号私信或者邮箱联系我,一定知无不言,言无不尽。
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
更多学习笔记见个人博客或关注微信公众号 < 呼延十 >——>呼延十

